طراحی شبکه های کامپیوتری

شبكه های محلی ( LAN ) اساس كار هر نوع ارتباط بين شبكه ای می باشند. در واقع يك ارتباط بين شبكه ای، ماحصل اتصال مجموعه ای از شبكه های محلی به يكديگر است. برای ايجاد يك شبكه محلی می توان از مجموعه ای دستگاه های شبكه ای (نظير سوئيچ، روتر و هاب) و فناوری استفاده نمود. با استفاده از دستگاه های فوق، می توان هاست های متعددی را به يكديگر متصل و يك شبكه محلی را ايجاد نمود. در ادامه و در صورت ضرورت می توان يك شبكه محلی را به شبكه محلی ديگر متصل تا يك ارتباط بين شبكه ای ايجاد گردد.
تعداد شبكه ها و ضرورت استفاده از آنها در ساليان اخير به شدت رشد يافته است. شبكه های امروزی می بايست به منظور تامين طيف گسترده ای از خواسته ها نظير اشتراك داده و يا چاپگر و درخواست هائی خاص نظير ويدئو كنفرانس دارای سرعتی قابل قبول و مناسب باشند. علاوه بر ضرورت به اشتراك گذاشتن منابع بر روی يك شبكه اين نياز بيش از گذشته احساس می شود كه بتوان شبكه های متعددی را به يكديگر متصل تا كاربران آنها بتوانند از منابع موجود بر روی هر شبكه استفاده نمايند. همواره اين احتمال وجود دارد كه مجبور شويم يك شبكه بزرگ را به چندين شبكه كوچكتر تقسيم نمائيم. چرا كه به موازات رشد شبكه و افزايش ترافيك آن، زمان پاسخ به كاربران بتدريج كاهش خواهد يافت.

افزايش ترافيك و يا شلوغی شبكه (Congestion ) يكی از مسائل مهم در شبكه های كامپيوتری است كه عوامل مختلفی در ايجاد آن موثر می باشند:
• وجود هاست های فراوان در يك broadcast domain
• Broadcasts بيش از اندازه
• Multicasting
• پهنای باند كم و نارسا
• استفاده از هاب برای ارتباطات شبكه
• وجود حجم بالائی از ترافيك ARP و يا IPX (پروتكل روتينگ شركت ناول كه نظير IP است ولی به شدت پرحرف! است)
برای حل مشكلات فوق و كاهش بار ترافيكی شبكه می توان يك شبكه بزرگ را به چندين شبكه كوچكتر تقسيم نمود. به اين كار segmentation گفته می شود و برای تحقق آن از روتر، سوئيچ و bridge استفاده می گردد. .
روتر
از روترها برای اتصال شبكه ها و مسيريابی بسته های اطلاعاتی از يك شبكه به شبكه ديگر استفاده می گردد. روترها به صورت پيش فرض باعث تفكيك broadcast domain می گردند. به مجموعه ای از دستگاه های موجود بر روی يك شبكه كه به broadcast ارسالی بر روی سگمنت گوش می دهند، broadcast domain گفته می شود. تفكيك broadcast domain در يك شبكه بسيار حائز اهميت است چر اكه پس از ارسال broadcast توسط يك هاست و يا سرويس دهنده، هر دستگاه موجود در شبكه می بايست آن را دريافت و پردازش نمايد. در صورت استفاده از روتر، زمانی كه اينترفيس آن يك broadcast را دريافت می نمايد، می تواند آن را بدون نياز فورواردينگ به شبكه ديگر، دور بياندازد. با اين كه روترها به صورت پيش فرض به عنوان دستگاه هائی جهت تفكيك broadcast domain مطرح و شناخته شده می باشند ولی لازم است به اين نكته مهم نيز توجه گردد كه روترها قادر به تفكيك collision domains نيز می باشند.
برای كاهش ازدحام و يا شلوغی شبكه توسط روتر از روش های متعددی استفاده می گردد:
• روترها به صورت پيش فرض broadcast را فوروارد نمی نمايند ( سوئيچ و bridge اين كار را انجام نمی دهند).
• روترها قادر به فيلترينگ شبكه بر اساس اطلاعات لايه سه می باشند ( مبتنی بر آدرس های IP ). سوئيچ و bridge اين كار را انجام نمی دهند.
از روترها در شبكه برای تامين اهداف زير استفاده می گردد:
• سوئيچينگ بسته های اطلاعاتی
• فيلترينگ بسته های اطلاعاتی
• ارتباطات بين شبكه ای
• انتخاب مسير و يا مسيريابی
سوئيچ
از سوئيچ های LAN برای ارتباطات بين شبكه ای استفاده نمیگردد. در مقابل، از اين نوع دستگاه های شبكه ای برای افزودن قابليت های جديد به يك شبكه محلی استفاده می شود. مهمترين هدف از بكارگيری سوئيچ، بهبود كاركرد شبكه های محلی (بهينه سازی كارآئی) از طريق ارائه پهنای باند بيشتر برای كاربران شبكه است. سوئيچ ها نظير روتر، بسته های اطلاعاتی را به ساير شبكه ها فوروارد نمی نمايد. در مقابل آنها صرفا" فريم ها را از يك پورت به پورت ديگر فوروارد می نمايند. سوئيچ ها نمی توانند فريم ها را بين شبكه ها فوروارد نمايند و صرفا" می توانند حامل فريم ها برای روترها باشند تا توسط روترها به ساير شبكه ها فوروارد گردند.
به صورت پيش فرض، سوئيچ ها باعث تفكيك Collision domain در يك شبكه می شوند. Collision domain ، يك اصطلاح اترنتی است كه از آن به منظور تشريح سناريوی زير در يك شبكه استفاده می گردد:
• يك دستگاه خاص اقدام به ارسال يك بسته اطلاعاتی بر روی يك سگمنت شبكه می نمايد و اين تاكيد را دارد كه ساير دستگاه های موجود در سگمنت به آن توجه نمايند و در همان زمان دستگاهی ديگر در شبكه سعی در ارسال داده می نمايد. وضعيت فوق يك collision را در سگمنت ايجاد می نمايد. در زمان بروز collision، هر دو دستگاه می بايست مجددا" و پس از طی يك زمان تصادفی اقدام به ارسال مجدد داده نمايند. بديهی است كه ماهيت collision بگونه ای است كه در نهايت كاهش كارآئی يك شبكه را به دنبال خواهد داشت.
با توجه به اين كه هاب صرفا" يك collision domain و يك broadcast domain را ارائه می نمايد، استفاده از آن كارآئی شبكه را به شدت كاهش می دهد. در اينچنين شبكه هائی، هر هاست موجود در سگمنت به يكی از پورت های هاب متصل می گردد. در مقابل، هر پورت موجود در يك سوئيچ collision domain مربوط به خود را ارائه می نمايد. در واقع، سوئيچ ها collision domain جداگانه ای را ايجاد می نمايند ولی صرفا" يك broadcast domain را ارائه می نمايند. روترها broadcast domain جداگانه ای را ايجاد می نمايند.
bridge
از واژه bridging قبل از پياده سازی هاب و روتر، استفاده می گرديد. بنابراين طبيعی است كه برخی افراد از bridge به عنوان سوئيچ ياد كنند. در واقع، سوئيچ و bridge دارای عملكردی مشابه می باشند. دو دستگاه فوق collision domain در يك شبكه محلی را تفكيك می نمايند. اين بدان معنی است كه سوئيچ اساسا" يك bridge چندين پورت با قدرت اداراك بيشتری است. علی رغم وجود شباهت های زياد بين سوئيچ و bridge تفاوت هائی نيز در اين رابطه وجود دارد. به عنوان نمونه سوئيچ ها به منظور انجام وظايف خود دارای امكانات مديريتی و قابليت های پيشرفته ای می باشند. در اغلب موارد bridge صرفا" دارای يك، دو و يا چهار پورت می باشد. از bridge زمانی در شبكه استفاده می شود كه هدف كاهش collision در broadcast domain و افزايش collision domain در شبكه است. در چنين وضعيتی bridge پهنای باند بيشتری را برای كاربران ارائه می نمايد. يكی از مزايای اوليه bridging ، افزايش پهنای باند قابل دسترس بر روی يك سگمنت شبكه است، چراكه با اين كار تعداد دستگاه های موجود در يك collision domain كاهش می يابد.
استفاده از روتر، سوئيچ و bridge در شبكه
شكل زير نحوه استفاده از تجهيزات شبكه ای فوق را در يك شبكه فرضی نشان می دهد. در شكل فوق سه شبكه فرضی ( شبكه متصل شده از طريق هاب در قسمت پائين شكل، شبكه متصل شده از طريق سوئيچ در قسمت سمت چپ شكل و شبكه متصل شده از طريق bridge در قسمت بالای شكل ) از طريق روتر به يكديگر متصل شده اند.
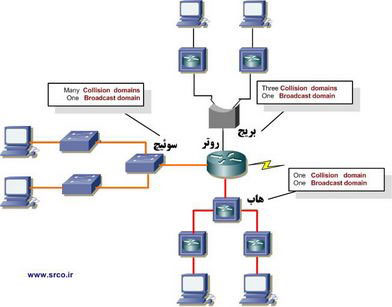
• همانگونه كه در شكل فوق مشاهده می نمائيد از روتر در مركز شبكه استفاده شده است. علت اين كار استفاده از فناوری های قديمی تر نظير هاب و bridge است. در صورتی كه صرفا از سوئيچ استفاده گردد، در سناريوی فوق تغييرات عمده ای ايجاد خواهد شد.
• در شبكه های جديد می توان سوئيچ را در مركز شبكه قرار داد و از روتر برای اتصال شبكه های منطقی به يكديگر استفاده نمود. در صورتی كه قصد پياده سازی اينچنين شبكه هائی را داشته باشيم، می بايست شبكه های محلی مجازی ( VLANs ) را ايجاد نمود.
• در قسمت بالای شكل فوق از يك bridge استفاده شده است تا به كمك آن هر دو هاب به روتر متصل شوند. همانگونه كه اشاره گرديد، bridge باعث تفكيك collision domain می گردد ولی تمامی هاست های متصل شده به هر دو هاب همچنان در يك broadcast domain مشابه قرار می گيرند. همچنين، bridge فوق صرفا دو collision domain را ايجاد كرده است. بنابراين هر دستگاه متصل شده به يك هاب در يك collision domain مشابه قرار می گيرد.
• در قسمت پائين شكل فوق، سه عدد هاب متصل شده به هم به روتر متصل شده اند. وضعيت فوق باعث ايجاد يك collision domain بزرگ و يك broadcast domain بزرگ می شود.
• بهترين شبكه متصل شده به روتر، شبكه متصل شده از طريق سوئيچ موجود در قسمت سمت چپ شكل فوق است. چرا ؟ چون هر پورت موجود بر روی سوئيچ باعث تفكيك collision domain می گردد. ولی اين يك وضعيت مطلوب نمی باشد چون تمامی دستگاه ها همچنان در يك broadcast domain مشابه قرار داشته و می بايست به تمامی broadcast ارسالی گوش فرا دهند و اگر broadcast domain خيلی بزرگ باشد، كاربران پهنای باند كمتری را داشته و می بايست broadcast بيشتری را پردازش نمايند. ماحصل اين وضعيت، كاهش زمان پاسخ شبكه به كاربران خواهد بود.
• بهترين شبكه، شبكه ای است كه به درستی پيكربندی و منطبق بر نياز يك سازمان باشد. سوئيچ ها به همراه روترها زمانی كه به درستی در يك شبكه كنار هم قرار داده شوند، طراحی شبكه بهترين وضعيت ممكن را پيدا خواهد كرد.
• در شبكه فوق، نه collision domain و سه broadcast domain وجود دارد.
• مشاهده broadcast domain در شكل فوق ساده است چراكه روتر به صورت پيش فرض broadcast domain را تفكيك می نمايد و از آنجائی كه روتر فوق دارای سه اتصال است، سه broadcast domain ايجاد می گردد.
• مشاهده collision domain در شكل فوق به سادگی broadcast domain نمی باشد. تمامی شبكه متصل شده از طريق هاب دارای يك collision domain است. شبكه متصل شده از طريق bridge شامل سه collision domain و شبكه متصل شده از طريق سوئيچ شامل پنج collision domain است ( يكی برای هر پورت سوئيچ). بنابراين در مجموع نه collision domain در شبكه فوق وجود دارد.
طراحی يك مدل آدرس دهی IP منطبق بر طرح شبكه
آدرس IP ، يك شناسه عددی است كه به هر ماشين موجود بر روی يك شبكه IP نسبت داده می شود. آدرس فوق، مكان خاص يك دستگاه بر روی شبكه را مشخص می نمايد. آدرس IP يك آدرس نرم افزاری است (نه يك آدرس سخت افزاری). هر اينترفيس شبكه دارای يك آدرس سخت افزاری نيز می باشد كه از آن به منظور يافتن هاست بر روی يك شبكه محلی استفاده می گردد. آدرس دهی مبتنی بر IP ، امكان مبادله اطلاعات بين هاست موجود در يك شبكه محلی با هاست موجود بر روی شبكه ديگر صرفنظر از نوع شبكه محلی را فراهم می نمايد.
در زمان طراحی مدل آدرس دهی IP در يك شبكه، می بايست به مواردی متعددی توجه شود چراكه با در نظر گرفتن برخی ملاحظات در زمان طراحی، نگهداری شبكه در مدت زمان حيات آن راحت تر می گردد.
اصطلاحات IP
• بيت ( bit ): يك بيت شامل يك رقم است. صفر و يا يك
• بايت ( byte ): يك بايت بسته به اين كه از parity استفاده شده باشد از هفت و يا هشت بيت تشكيل می گردد. در ادامه همواره فرض ما بر اين است كه يك بايت از هشت بيت تشكيل شده است.
• اكتت ( octet ): يك اكتت از هشت بيت تشكيل می گردد و صرفا" يك عدد هشت بيتی در مبنای دو را نشان می دهد. در ادامه به دفعات از واژه های بايت و اكتت به جای هم استفاده شده است.
• آدرس شبكه ( Network address ): از آدرس شبكه به منظور روتينگ و ارسال بسته های اطلاعاتی به يك شبكه راه دور استفاده می شود. آدرس های 0 . 0 . 0 . 10 و 0 . 10 . 168 . 192 نمونه هائی در اين زمينه می باشند.
• آدرس پخش ( Broadcast address ): از آدرس های فوق، برنامه ها و هاست ها جهت ارسال اطلاعات برای تمامی گره های موجود در يك شبكه استفاده می نمايند.
مدل آدرس دهی سلسله مراتبی IP
يك آدرس IP شامل 32 بيت اطلاعات است. اين بيت ها به چهار بخش تقسيم می گردند كه به هر بخش بايت و يا اكتت گفته می شود. هر بايت و اكتت شامل هشت بيت می باشد.
برای نمايش يك آدرس IP می توان از روش های متعددی استفاده نمود:
• دهدهی - جدا شده توسط نقطه ( 56 . 30 . 16 . 172 )
• باينری يا مبنای دو ( 00111000 . 00011110 . 00010000 . 10101100 )
• مبنای شانزده ( AC.10.1E.38 )
تمامی مثال های فوق يك آدرس IP مشابه را نمايش می دهند. در زمان بحث بر روی آدرس دهی IP از مبنای شانزده به ميزانی كه از "دهدهی - جدا شده توسط نقطه" و يا باينری استفاده می شود، استفاده نمی گردد. در برخی برنامه ها ممكن است از يك آدرس IP به صورت مبنای شانزده استفاده گردد. ريجستری ويندوز يك نمونه مناسب از برنامه هائی است كه آدرس IP ماشين را به صورت مبنای شانزده ذخيره می نمايد.
آدرس سی و دو بيتی IP ، يك آدرس ساختيافته و يا سلسله مراتبی است ( در مقابل آدرس های غيرسلسله مراتبی و flat . با اين كه می توان از هر نوع مدل آدرس دهی استفاده نمود، ولی توصيه می گردد كه از آدرس دهی سلسله مراتبی استفاده شود. ارائه تعداد بسيار زيادی آدرس، مزيت عمده استفاده از يك مدل آدرس دهی سلسله مراتبی است با توجه به اين كه آدرس IP سی و دو بيتی است و هر بيت می تواند مقدار صفر و يا يك را دارا باشد، در مجموع دو به توان سی و دو آدرس را خواهيم داشت ( 3 / 4 ميليارد و يا 4,294,967,296 ).
اشكال مدل آدرس دهی flat و علت عدم استفاده از آن برای آدرس دهی IP به روتينگ مربوط می گردد. در صورتی كه هر آدرس منحصربفرد باشد، تمامی روترهای موجود در اينترنت می بايست آدرس هر ماشين موجود در اينترنت را ذخيره نمايند.
اين موضوع روتينگ موثر را غيرممكن می سازد حتی اگر صرفا" بخشی از آدرس های موجود استفاده شده باشد. برای حل اين مشكل می توان از مدل آدرسی دهی سلسله مراتبی با دو و يا سه سطح استفاده نمود كه در آن آدرس ها بر اساس شبكه، هاست ( دو سطح ) و يا شبكه، زير شبكه و هاست (سه سطح ) سازماندهی می شوند. مدل آدرس دهی سلسله مراتبی ( با دو و يا سه سطح ) را می توان با يك شماره تلفن مقايسه نمود. در يك شماره تلفن، بخش اول مربوط به كد شهر است.
بخش دوم مربوط به يك ناحيه محلی در شهر مورد نظر است و بخش نهائی شماره مشترك است. آدرس های IP از يك ساختار لايه ای مشابه استفاده می نمايند. در مقابل اين كه تمامی سی و دو بيت به عنوان يك شناسه منحصربفرد در نظر گرفته شود ( نظير مدل آدرس دهی flat ) ، بخشی از آدرس، شامل آدرس شبكه و ساير بخش ها به عنوان زيرشبكه و يا هاست ( سه سطح ) و يا صرفا" آدرس هاست ( دو سطح ) در نظر گرفته می شود.
آدرس دهی شبكه
آدرس شبكه كه به آن شماره شبكه نيز گفته می شود، بطور منحصربفرد هر شبكه را مشخص می نمايد. آدرس شبكه هر ماشين موجود بر روی يك شبكه مشابه، به عنوان بخشی از آدرس IP آن در نظر گرفته می شود. در آدرس IP:172.16.30.56 ، اعداد 16 . 172 آدرس شبكه را مشخص می نمايد.
آدرس گره بطور منحصربفرد هر ماشين موجود بر روی يك شبكه را مشخص می نمايد. آدرس گره می بايست منحصربفرد باشد چراكه اين آدرس يك ماشين خاص موجود بر روی يك شبكه را شناسائی می نمايد. به عدد فوق ( آدرس گره ) به عنوان يك آدرس هاست مراجعه می گردد. در نمونه آدرس IP:172.16.30.56 ، اعداد 56 . 30 آدرس گره را مشخص می نمايد.
طراحان اينترنت، با توجه به اندازه شبكه تصميم به ايجاد كلاس های مختلف شبكه نموده اند:
• برای تعداد شبكه های اندكی كه گره های فراوانی را شامل می شوند، كلاس A در نظر گرفته شده است.
• برای تعداد شبكه های زيادی كه دارای گره های كمتری می باشند، كلاس C در نظر گرفته شده است .
• برای شبكه های بين شبكه های بسيار بزرگ و بسيار كوچك، كلاس B در نظر گرفته شده است .
تقسيم يك آدرس IP به آدرس يك شبكه و گره ( هاست ) توسط كلاس استفاده شده در شبكه مشخص می گردد. شكل زير كلاس های مختلف شبكه را نشان می دهد:
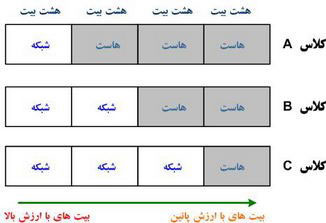
برای اطمينان از روتينگ موثر، طراحان اينترنت يك قانون را برای بخش بيت های آغازين آدرس هر يك از كلاس های مختلف شبكه تعريف كرده اند. مثلا، با توجه به اين كه يك روتر می داند كه آدرس های شبكه كلاس A همواره با صفر شروع می شوند، وی می تواند صرفا پس از خواندن اولين بيت آدرس مورد نظر با سرعت قابل قبول يك بسته اطلاعاتی را به مقصد مورد نظر هدايت نمايد. اين موضوع نكته مهم در خصوص مدل تعريف شده و وجه تمايز بين آدرس های كلاس A ، كلاس B و كلاس C می باشد. در ادامه به بررسی كلاس های مختلف شبكه خواهيم پرداخت.
كلاس A
•در يك آدرس شبكه كلاس A ، اولين بايت به آدرس شبكه اختصاص يافته است و سه بايت باقيمانده برای آدرس گره ها در نظر گرفته شده است. فرمت كلاس A به صورت network.node.node.node می باشد. به عنوان مثال در آدرس 49.22.102.70 ، عدد 49 آدرس شبكه و 70 . 102 . 22 آدرس گره را مشخص می نمايد. هر ماشين موجود بر روی اين شبكه خاص می بايست دارای آدرس شبكه 49 باشد.
•طول آدرس های شبكه كلاس A صرفا" يك بايت است. بيت اول اين بايت رزو شده و از هفت بيت باقيمانده برای آدرس دهی استفاده می گردد. بدين ترتيب، حداكثر 128 شبكه كلاس A را می توان ايجاد نمود ( دو به توان هفت ).
•اولين بيت مربوط به اولين بايت در يك آدرس شبكه كلاس A می بايست همواره صفر باشد. اين بدان معنی است كه يك آدرس كلاس A می بايست بين صفر و 127 باشد. با توجه به اين كه در آدرس های كلاس A صرفا يك بايت برای آدرس شبكه در نظر گرفته می شود در صورتی كه اين آدرس را با توجه به محدوديت اشاره شده ( مقدار صفر اولين بيت در بايت مربوطه ) به صورت 0xxxxxxx در نظر بگيريم و در ابتدا تمامی هفت بيت باقيمانده را صفر (00000000) و در مرتبه دوم يك ( 01111111) در نظر بگيريم، محدوده آدرس های شبكه كلاس A مشخص می گردد ( بين صفر تا 127 ).
•آدرس شبكه تمام صفر ( 0000 0000 )، برای مسير پيش فرض رزو شده می باشد. همچنين آدرس 127 برای اشكال زدائی رزو شده است و نمی توان از آن استفاده نمود. بدين ترتيب، تعداد واقعی آدرس های شبكه كلاس A معادل 126 می باشد ( 126 = 2 - 128 ).
• هر آدرس كلاس A دارای سه بايت ( 24 بيت ) برای آدرس دهی يك ماشين در شبكه است. اين بدان معنی است كه به تعداد دو به توان 24 ( معادل 16,777,216 ) آدرس وجود خواهد داشت كه بطور منحصربفرد برای آدرس دهی گره ها در هر شبكه كلاس A استفاده می شود. با توجه به اين كه آدرس های گره تمام صفر و تمام يك رزو شده می باشند تعداد واقعی گره ها برای يك شبكه كلاس A معادل 16,777,214 ( دو به توان 24 منهای دو ) میباشد. بدين ترتيب می توان تعداد بسيار فراوانی هاست را بر روی يك سگمنت شبكه آدرس دهی و استفاده نمود
برای استخراج محدوده آدرس های معتبر هاست ها در يك شبكه كلاس A می توان از روش زير استفاده نمود:
• در صورت صفر كردن تمامی بيت های مربوط به هاست ( سه بايت )، آدرس شبكه مشخص می گردد:
0 . 0 . 0 . 10
• در صورت يك كردن تمامی بيت های مربوط به هاست ( سه بايت )، آدرس broadcast مشخص می گردد: 255 . 255 . 255 . 10
هاست های معتبر، اعداد بين آدرس شبكه و آدرس broadcast می باشند. ( در مثال فوق از 1 . 0 . 0 . 10 تا 254 . 255 . 255 . 10 ). بخاطر داشته باشيد در مواردی كه سعی در يافتن آدرس های معتبر هاست می نمائيد، بيت های هاست نمی توانند تمام صفر و يا تمام يك باشند.
كلاس B
•در يك آدرس شبكه كلاس B ، دو بايت اول اختصاص به آدرس شبكه دارد و از دو بايت باقيمانده برای آدرس دهی گره استفاده می گردد. فرمت آدرس های كلاس B به صورت network.network.node.node می باشد. به عنوان نمونه آدرس 172.16.30.56 ، آدرس شبكه 16 . 172 و آدرس گره 56 . 30 است.
•اولين بيت مربوط به اولين بايت می بايست همواره مقدار يك و دومين بيت همواره مقدار صفر را داشته باشد. در صورتی كه ساير بيت های باقيمانده در بايت اول را صفر (10000000) و يا يك ( 10111111 ) در نظر بگيريم محدوده شبكه های كلاس B مشخص می گردد. (بين 128 تا 191 ) .
•برای آدرس شبكه دو بايت در نظر گرفته شده است. بدين ترتيب، دو به توان 16 عدد شناسه منحصربفرد برای آدرس دهی شبكه وجود خواهد داشت ولی با توجه به اين كه تمامی آدرس های شبكه كلاس B می بايست با 1 و صفر شروع شوند ( دو بيت رزو شده )، برای آدرس دهی شبكه از 14 بيت باقيمانده استفاده خواهد شد. بنابراين در نهايت دو به توان 14 شناسه منحصر بفرد (16,384) برای آدرس دهی شبكه های كلاس B وجود خواهد داشت.
•در آدرس های كلاس B از دو بايت برای آدرس دهی گره ها استفاده می شود. اين بدان معنی است كه به تعداد دو به توان 16 منهای دو ( تمام صفر و تمام يك ) يعنی معادل 65,534 گره را می توان برای هر شبكه كلاس B آدرس دهی نمود.
برای استخراج محدوده آدرس های معتبر هاست ها در يك شبكه كلاس B می توان از روش زير استفاده نمود:
•در صورت صفر كردن تمامی بيت های مربوط به هاست ( دو بايت )، آدرس شبكه مشخص می گردد:
0 . 0 . 16 . 172
•در صورت يك كردن تمامی بيت های مربوط به هاست ( دو بايت )، آدرس broadcast مشخص می گردد: 255 . 255 . 16 . 172
هاست های معتبر، اعداد بين آدرس شبكه و آدرس broadcast می باشند. ( در مثال فوق از 1 . 0 . 16 . 172 تا 254 . 255 . 16 . 172 )
كلاس C
• سه بايت اول آدرس های كلاس C به بخش آدرس شبكه و صرفا يك بايت باقيمانده به آدرس گره اختصاص می يابد. فرمت آدرس های كلاس C به صورت: network.network.network.node است. به عنوان نمونه در آدرس IP:192.168.100.102 ، آدرس شبكه 100 . 168 . 192 و آدرس گره 102 می باشد.
• در شبكه های كلاس C ، دو بيت اولين اكتت يك و سومين بيت همواره صفر است (110). برای مشخص كردن محدوده آدرس های شبكه كلاس C پس از دنبال نمودن فرآيندی مشابه با آنچه كه در مورد كلاس A و B اشاره گرديد می توان محدوده شبكه های كلاس C را بدست آورد ( بين 192 تا 223 ). بنابراين در صورت مشاهده يك آدرس IP كه شروع آن با 192 تا 223 است، مشخص می گردد كه آدرس فوق يك آدرس IP كلاس C می باشد.
• در يك آدرس شبكه كلاس C ، سه بيت اول بايت اول 110 می باشد. بدين ترتيب می توان با انجام محاسباتی ساده تعداد شبكه دردسترس كلاس C را مشخص نمود. 3 بايت ( و يا 24 بيت ) منهای سه بخش رزو شده، 21 بيت جهت آدرس دهی را ارائه می نمايد كه به كمك آنها می توان به تعداد 2 به توان 21 و يا 2,097,152 شبكه كلاس C را ايجاد نمود.
• هر شبكه منحصربفرد كلاس C از يك بايت برای آدرس دهی گره ها استفاده می نمايد. بدين ترتيب به تعداد دو به توان 8 و يا 256 منهای دو آدرس رزو شده ( تمام صفر و يا تمام يك ) را می توان برای هر شبكه كلاس C آدرس دهی نمود ( 254 گره).
برای استخراج محدوده آدرس های معتبر هاست ها در يك شبكه كلاس C می توان از روش زير استفاده نمود:
• در صورت صفر كردن تمامی بيت های مربوط به هاست ( يك بايت )، آدرس شبكه مشخص می گردد:
0 . 100 . 168 . 192
• در صورت يك كردن تمامی بيت های مربوط به هاست ( يك بايت )، آدرس broadcast مشخص می گردد: 255 . 100 . 168 . 192
هاست های معتبر، اعداد بين آدرس شبكه و آدرس broadcast می باشند. ( در مثال فوق از 1 . 100 . 168 . 192 تا 254 . 100 . 168 . 192 ).
كلاس های D و E
آدرس های بين 224 و 255 برای شبكه های كلاس D و E رزو شده اند. از كلاس D ( بين 224 تا 239 ) برای آدرس های multicast و از كلاس E ( بين 240 تا 255 ) برای اهداف علمی و تحقيقاتی استفاده می گردد.
آدرس های رزور شده
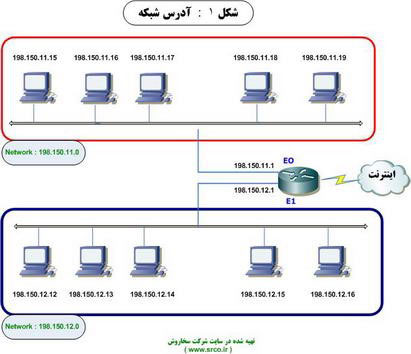
برخی از آدرس های IP برای اهداف خاصی رزو شده می باشند و مدير شبكه نمی تواند از اين نوع آدرس ها استفاده نمايد:
• آدرس هائی كه از آنها به منظور شناسائی و يا مشخص كردن خود شبكه استفاده می گردد. همانگونه كه در بخش بالای شكل زیر مشاهده می نمائيد، شبكه ای به آدرس 0 . 11 . 150 . 198 مشخص شده است ( يك شبكه كلاس C كه سه بايت اول آن آدرس شبكه و بايت آخر آدرس هاست را مشخص می نمايد ). مادامی كه داده بر روی شبكه محلی فوق حركت می نمايد و از يك هاست به هاست ديگر ارسال می گردد، شماره هاست حائز اهميت می باشد. زمانی كه داده ای از يك هاست موجود بر روی يك شبكه ديگر برای هر يك از هاست های موجود در اين شبكه ( محدوده آدرس های 1 . 11 . 150 . 198 تا 254 . 11 . 150 . 198 )، ارسال می گردد در مرحله اول شماره شبكه حائز اهميت خواهد بود، چراكه روتر با استفاده از آن قادر به فورواردينگ مناسب بسته اطلاعاتی به شبكه مقصد است ( مثلا" ارسال داده از شبكه ای به آدرس 0 . 11 . 159 . 198 ). شبكه محلی موجود در قسمت پائين شكل همانند شبكه محلی در بخش بالا عمل می نمايد با اين تفاوت كه شماره شبكه آن 0 . 12 . 150 . 198 است.
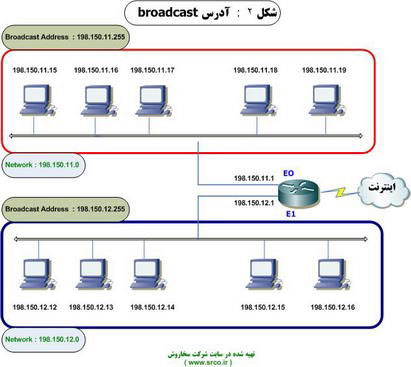
• آدرس های broadcast : از اين نوع آدرس ها جهت انتشار بسته های اطلاعاتی برای تمامی دستگاه های موجود بر روی يك شبكه استفاده می گردد. در قسمت بالای شكل 2، برای شبكه 0 . 11 . 150 . 198 آدرس broadcast برابر 255 . 11 . 150 . 198 می باشد. داده ای كه به آدرس broadcast ارسال می گردد توسط هر يك از هاست های موجود بر روی آن شبكه ( 0 . 11 . 150 . 198 ) خوانده می شوند. شبكه محلی نشان داده شده در بخش پائين شكل ( 0 . 12 . 150 . 198 ) نيز عملكردی مشابه با شبكه نشان داده شده در بخش بالا دارد با اين تفاوت كه آدرس broadcast آن معادل 255 . 12 . 150 . 198 می باشد.
آدرس broadcast
يك آدرس IP كه تمامی بيت های مربوط به هاست آن صفر باينری در نظر گرفته شده است، آدرس شبكه را مشخص می نمايد. اين آدرس رزو شده بوده و نمی توان از آن استفاده نمود. در شكل زیر، يك آدرس كلاس B كه تمامی بيت های مربوط به هاست آن صفر در نظر گرفته شده است، نشان داده شده است. آدرس 0 . 0. 10 . 176 ، آدرس شبكه را مشخص می نمايد.
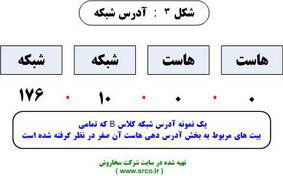
آدرس شبكه
در صورتی كه يك آدرس شبكه كلاس A را در نظر بگيريم ( در اين كلاس از سه بايت برای آدرس دهی هاست و از يك بايت برای آدرس دهی شماره شبكه استفاده می گردد )، آدرس 0 . 0 . 0 . 113 آدرس IP شبكه ای است كه می تواند شامل هاستی به آدرس 3 . 2 . 1 . 113 باشد. روترها از آدرس های شبكه در زمان فورواردينگ بسته های اطلاعاتی بر روی شبكه استفاده می نمايند. در يك آدرس شبكه كلاس B برای دو اكتت و يا بايت اوليه به صورت پيش فرض مقدار در نظر گرفته می شود. از دو بايت و يا اكتت آخر برای شماره هاست و مشخص نمودن دستگاه های متصل شده به شبكه استفاده می گردد. به اين نوع آدرس ها اصطلاحا" unicast گفته می شود. يك آدرس unicast صرفا" به يك هاست بر روی يك شبكه اشاره می نمايد. در مثال فوق آدرس IP: 176.10.0.0 برای آدرس شبكه رزو شده است و نمی توان آن را به هيچيك از دستگاه های متصل شده به اين شبكه نسبت داد. در چنين مواردی می توان به عنوان نمونه از آدرس 1 . 16 . 10 . 176 برای آدرس دهی يكی از هاست های موجود بر روی شبكه 0 . 0. 10 . 176 استفاده نمود. در اين مثال 10 . 176 بخش مربوط به آدرس شبكه و 1 . 16 بخشی است كه آدرس يك هاست را بر روی شبكه فوق مشخص می نمايد. برای ارسال داده به تمامی دستگاه های موجود بر روی يك شبكه به يك آدرس broadcast نياز خواهيم داشت. broadcast زمانی اتفاق می افتد كه يك فرستنده اقدام به ارسال داده برای تمامی دستگاه های موجود در يك شبكه می نمايد. شكل زیر، آدرس broadcast و شبكه يك نمونه آدرس كلاس B را نشان می دهد:

آدرس broadcast و شبكه يك نمونه آدرس كلاس B
آدرس broadcast شبكه فوق 255 . 255 . 10 . 176 می باشد. بسته های اطلاعاتی حاوی چنين آدرس مقصدی توسط هر يك از كامپيوترهای موجود بر روی شبكه ( 0 . 0 . 10 . 176 ) دريافت و پردازش می گردد. برای حصول اطمينان از اين موضوع كه ساير دستگاه های موجود در شبكه پيام broadcast را پردازش می نمايند، فرستنده می بايست از يك آدرس IP خاص مقصد استفاده نمايد تا هر يك از دستگاه های گيرنده بتوانند آن را شناسائی و پردازش نمايند. آدرس های broadcast در بخش هاست خود دارای مقدار يك می باشند ( تمامی بيت های مربوط به بخش هاست در آدرس IP ، يك باينری در نظر گرفته می شود ).
برای شبكه 0 . 0 . 10 . 176 كه شانزده بيت آن مربوط به آدرس دهی هاست است، آدرس 255 . 255 . 10 . 176 به عنوان آدرس broadcast در نظر گرفته می شود.
آدرس های عمومی و خصوصی
ثبات و انسجام اينترنت به يكتائی عمومی آدرس های شبكه بستگی دارد. همانگونه كه در شكل زیر مشاهده می نمائيد، مدل آدرس دهی شبكه فوق دارای مشكل جدی است. هر دو شبكه دارای يك آدرس شبكه 0 . 11 . 150 . 198 می باشند. زمانی كه داده ارسالی به روتر می رسد، وی آن را می بايست برای كدام شبكه فوروارد نمايد .
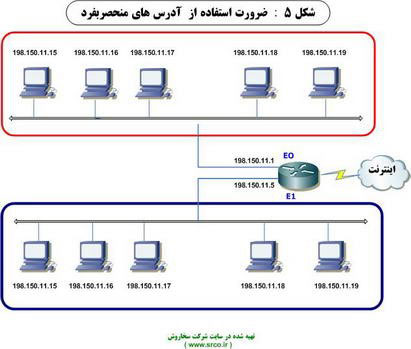
ضرورت استفاده از آدرس های منحصربفرد
مدلی اينچنين، افزايش بار ترافيكی شبكه را به دنبال داشته و می تواند در عمل روتر را به منظور انجام وظايف خود با شكست مواجه نمايد. بنابراين، می بايست از مكانيزم های خاصی به منظور حصول اطمينان از يكتائی آدرس ها استفاده گردد. اين مسئوليت در ابتدا به InterNIC ( برگرفته شده از Internet Network Information Center ) واگذار گرديد. اين سازمان هم اينك غيرفعال است و مسئوليت واگذار شده به آنها توسط موسسه IANA ( برگرفته شده از Internet Assigned Numbers Authority ) دنبال می گردد. اين سازمان با دقت مديريت آدرس های IP را با هدف عدم تكرار در آدرس های عمومی انجام می دهد.
آدرس های IP عمومی منحصربفرد می باشند و نمی بايست ماشين های متصل شده به يك شبكه عمومی دارای آدرس های IP مشابه باشن . چراكه آدرس های IP عمومی، سراسری و استاندارد می باشند. تمامی ماشين های متصل شده به اينترنت می بايست به اين قانون وفادار و پايبند باشند. آدرس های IP عمومی را می توان از يك مركز ارائه دهنده خدمات اينترنت ( ISP ) و ساير مراكز قانونی دريافت كرد. با توجه به رشد سريع اينترنت، تعداد آدرس های IP عمومی جوابگو نمی باشند. به همين دليل و در جهت حل اين بحران، مدل های آدرس دهی جديدی نظير CIDR ( برگرفته شده از classless interdomain routing ) و يا IPv6 ، پياده سازی شده است. يكی ديگر از راه حل های پياده سازی شده به منظور حل مشكل فوق، استفاده از آدرس های خصوصی است. همانگونه كه اشاره گرديد، هاست های اينترنت نيازمند يك آدرس IP منحصربفرد جهانی می باشند. شبكه های محلی كه به اينترنت متصل نشده اند می توانند از هر آدرس معتبری استفاده نمايند ( بشرطی كه بر روی شبكه خصوصی منحصربفرد باشند) . امروزه تعداد زيادی از شبكه های خصوصی در كنار شبكه های عمومی وجود دارد كه ممكن است سرانجام به اينترنت متصل شوند. بر اساس RFC 1918 سه بلاك از آدرس های IP برای شبكه های خصوصی در نظر گرفته شده است ( يك كلاس A ، يك مجموعه از آدرس های كلاس B و يك مجموعه از آدرس های كلاس C ). آدرس هائی از اين نوع بر روی ستون فقرات اينترنت روت نشده و روترهای اينترنت بلافاصله آدرس های خصوصی را دورخواهند انداخت. جدول زير محدوده آدرس های خصوصی را نشان می دهد.
|
كلاس IP
|
محدوده آدرس های خصوصی تعريف شده
|
|
Class A
|
10.0.0.0 to 10.255.255.255
|
|
Class B
|
172.16.0.0 to 172.31.255.255
|
|
Class C
|
192.168.0.0 to 192.168.255.255
|
آدرس های IP خصوصی
در صورتی كه قصد تعريف يك اينترانت غيرعمومی، يك آزمايشگاه تست و ... را داشته باشيم، می توان از اين نوع آدرس های خصوصی در مقابل آدرس های منحصربفرد سراسری استفاده نمود. آدرس های IP خصوصی می توانند با آدرس های IP عمومی تركيب گردند. برای اتصال شبكه ای كه از آدرس های IP خصوصی استفاده می نمايد به اينترنت، نيازمند ترجمه آدرس های خصوصی به آدرس های عمومی می باشيم. به اين فرآيند ترجمه، NAT ( برگرفته شده از Network Address Translation ) گفته می شود. معمولا روتر دستگاهی است كه عمليات NAT را انجام می دهد.
سه نوع مختلف NAT وجود دارد:
•NAT ايستا: در اين مدل يك تناظر يك به يك بين آدرس های محلی و سراسری ايجاد می گردد. بدين ترتيب، مجبور خواهيم بود كه برای هر هاست موجود بر روی شبكه محلی دارای يك آدرس IP واقعی باشيم.
•NAT پويا : در اين مدل يك آدرس IP خصوصی به يك آدرس IP عمومی map می شود. فرآيند فوق بر اساس مجموعه ای از آدرس های IP عمومی ذخيره شده در يك pool انجام می گردد. بدين ترتيب لازم نخواهد بود كه همانند NAT ايستا پيكربندی روتر برای ايجاد تناطر يك به يك به صورت دستی انجام شود. توجه داشته باشيد كه در اين مدل می بايست به تعداد كافی از آدرس های IP واقعی استفاده گردد تا هر هاست امكان مبادله بسته های اطلاعاتی بر روی اينترنت را داشته باشد.
• NAT overload : اين روش متداولترين نوع پيكربندی NAT است كه می توان آن را نوع خاصی از NAT پويا در نظر گرفت كه در آن چندين آدرس IP خصوصی صرفا به يك آدرس IP عمومی با استفاده از پورت های مختلف map می شوند ( مدل many-to-one ). به اين مدل PAT ( برگرفته شده از port address translation ) نيز گفته می شود. با استفاده از PAT ( و يا NAT Overload )، می توان هزاران كاربر را صرفا" با استفاده از يك آدرس IP واقعی به اينترنت متصل نمود . سرويس فوق ، دليلی است بر اين موضوع كه چرا تا كنون با بحران كمبود آدرس IP در اينترنت مواجه نشده ايم.
مفاهيم اوليه مسیریابی
به گرفتن يك بسته اطلاعاتی از دستگاهی و ارسال آن از طريق شبكه برای دستگاه موجود بر روی يك شبكه متفاوت، روتينگ گفته می شود. روترها برای انجام روتينگ با هاست های موجود بر روی شبكه ها كاری نداشته و صرفا در خصوص شبكه ها و انتخاب بهترين مسير تصميم گيری می گيرند . روترها بر اساس آدرس منطقی شبكه ای كه هاست مورد نظر بر روی آن مستقر است، بسته اطلاعاتی را دريافت و در ادامه، از آدرس سخت افزاری هاست برای توزيع بسته اطلاعاتی از روتر به مقصد صحيح هاست استفاده می نمايند. در روتينگ پويا، پروتكل موجود بر روی يك روتر با پروتكل مشابه اجراء شده بر روی روترهای همسايه ارتباط برقرار می نمايد. در ادامه، هر يك از روترها اطلاعات مربوط به شبكه هائی را كه نسبت به آنها آگاهی دارند به اطلاع هم رسانده تا در جدول روتينگ خود ذخيره نمايند. بدين ترتيب و بر اساس فرآيند فوق دانش روترها نسبت به شبكه هائی كه آنها را می شناسند، بهنگام می گردد. در صورت بروز تغيير در شبكه، پروتكل های روتينگ پويا بطور اتوماتيك اين موضوع را به اطلاع تمامی روترها می رسانند. در صورتی كه از روتينگ ايستا استفاده شده باشد، مديريت شبكه مسئول بهنگام سازی و اعمال تمامی تغييرات به صورت دستی در تمامی روترها می باشد. معمولا" در شبكه های بزرگ، تركيبی از دو روش روتينگ ايستا و پويا استفاده می گردد.
روتينگ ايستا
در روتينگ ايستا، مسيرها بطور دستی در هر يك از جداول روتينگ اضافه می گردد. اين روش دارای مزايا و محدوديت های مختص به خود است:
مزايای روتينگ ايستا
• عدم تحميل بار عملياتی اضافه بر روی پردازشگر روتر. بدين ترتيب می توان از يك روتر با پردازنده سبك تر استفاده نمود.
• برای بهنگام سازی اطلاعات موجود در جداول روتينگ از پهنای باند ( ظرفيت لينك های ارتباطی ) بين روترها استفاده نخواهد شد. بدين ترتيب هزينه لينك های ارتباطی WAN كاهش می يابد.
• امنيت، چراكه صرفا" مدير شبكه می تواند اجازه روتينگ به شبكه هائی خاص را فراهم نمايد.
محدوديت های روتينگ ايستا
• مديريت شبكه می بايست شناخت مناسب و واقعی از ارتباطات شبكه ای و نحوه اتصال روترها به يكديگر را بداند تا بتواند بر اساس آنها پيكربندی روترها را بطرز صحيح انجام دهد.
• در صورتی كه يك شبكه به مجموعه شبكه های ارتباطی اضافه گردد، مديريت شبكه می بايست يك مسير را برای آن در تمامی روترها و بطور دستی اضافه نمايد.
• روتينگ ايستا برای شبكه های بزرگ مناسب نمی باشد چراكه نگهداری اينچنين شبكه هائی مستلزم صرف زمان زيادی است.
روتنيگ پويا
در روتينگ پويا از پروتكل هائی به منظور يافتن و بهنگام سازی جداول روتينگ بر روی روترها استفاده می شود. در اين روش علاوه بر افزايش بار عملياتی پردازنده، درصدی از پهنای باند بين لينك های شبكه نيز اشغال خواهد شد. ( افزايش cost لينك ارتباطی ). در واقع، يك پروتكل روتينگ مجموعه ای از قوانين لازم به منظور ارتباط يك روتر با روترهای همسايه را تعريف می نمايد. IGP ( برگرفته شده از interior gateway protocols ) و EGP ( برگرفته شده از exterior gateway protocols ) دو نمونه از پروتكل های روتينگ می باشند كه از آنها در ارتباطات بين شبكه ای استفاده می گردد. از پروتكل IGP به منظور مبادله اطلاعات روتينگ با روترهای موجود در يك سيستم خود مختار و يا AS ( برگرفته شده از autonomous system ) استفاده می شود. يك سيستم و يا ناحيه خود مختار، شامل مجموعه ای از شبكه هائی است كه تحت يك حوزه مديريتی می باشند. اين بدان معنی است كه تمامی روترهائی كه اطلاعات جدول روتينگ مشابهی را به اشتراك می گذارند در يك ناحيه خود مختار مشابه قرار دارند. از پروتكل EGP برای ارتباط بين نواحی خودمختار استفاده می شود. BGP ( برگرفته شده از Border GatewayProtocol ) نمونه ای از يك پروتكل EGP است.
قبل از درگير شدن با پروتكل های روتينگ و آشنائی با نحوه عملكرد هر يك از آنها، می بايست به چند موضوع ديگر اشاره نمائيم. آشنائی با administrative distances و انواع محتلف پروتكل های روتينگ از جمله موضوعات مهم در اين رابطه است كه در ادامه به بررسی آنها خواهيم پرداخت.
Administrative Distances
در زمان پيكربندی پروتكل های روتينگ، می بايست به AD توجه خاصی داشت. از AD برای ارزش گذاری و ميزان قابليت اعتماد به اطلاعات روتينگ دريافتی يك روتر از طريق روتر همسايه اطلاق می گردد. AD ، يك عدد صحيح بين صفر تا 255 است كه عدد صفر نشاندهنده اعتماد بالا و عدد 255 نشاندهنده عدم وجود ترافيك بر روی مسير مورد نظر است. اگر روتری دو ليست بهنگام سازی را از يك شبكه راه دور مشابه دريافت نمايد، AD اولين چيزی است كه توسط وی كنترل خواهد شد. در صورتی كه يكی از مسيرهای توصيه شده و يا پيشنهادی دارای AD كمتری باشد، انتخاب و در جدول روتينگ ذخيره می گردد. در صورتی كه مسيرهای پيشنهادی برای يك شبكه مشابه دارای AD يكسانی می باشند، از متريك پروتكل روتينگ ( نظير تعداد hop و يا پهنای باند موجود بين خطوط ) استفاده خواهد شد و مسيری كه دارای متريك پائين تر و يا كمتری باشد در جدول روتينگ ثبت خواهد شد. در صورتی كه دو مسير پيشنهادی دارای AD و متريك يكسان باشند، پروتكل روتينگ از load-balance به شبكه راه دور استفاده می نمايد. جدول زير AD پيش فرض كه يك روتر سيسكو از آن به منظور اتخاذ تصميم در خصوص انتخاب مسير به يك شبكه راه دور استفاده می نمايد را نشان می دهد:
|
منبع مسير
|
AD پيش فرض
|
|
Connected interface
|
0
|
|
Static route
|
1
|
|
Enhanced Interior Gateway Routing Protocol (EIGRP)
|
90
|
|
Interior Gateway Routing Protocol (IGRP)
|
100
|
|
Open Shortest Path First (OSPF) protocol
|
110
|
|
Routing Information Protocol (RIP)
|
120
|
|
External EIGRP
|
170
|
|
Unknown
|
255
اين مسير هرگز استفاده نشده است
|
در صورتی كه يك شبكه مستقيما به روتر متصل شده باشد، روتر همواره از اينترفيس متصل شده به شبكه استفاده می نمايد. در صورتی كه مدير شبكه يك مسير ايستا را پيكربندی نماي، روتر به اين مسير بيش از هر نوع مسيری كه خود آموخته است، اعتماد خواهد كرد. مديران شبكه می توانند مقدار AD مسيرهای ايستا را تغيير دهند ولی به صورت پيش فرض، AD اين نوع مسيرها يك در نظر گرفته می شود. در صورتی كه دارای يك مسير ايستا، يك مسير توصيه شده RIP و يك مسير پيشنهادی IGRP از يك شبكه مشابه باشيم، روتر به صورت پيش فرض همواره از مسير ايستا استفاده خواهد كرد مگر اين كه AD مسير ايستا تغيير يابد.
انواع پروتكل های روتينگ
پروتكل های روتينگ را می توان به سه گروه عمده زير تقسيم نمود:
• Distance vector : در پروتكل های روتينگ Distance vector، بهترين مسير به يك شبكه راه دور بر اساس مسافت تعيين می شود. هر مرتبه كه يك بسته اطلاعاتی از يك روتر عبور می يابد ( كه به آن hop گفته می شود )، يك واحد به hop آن اضافه می شود. مسيری كه دارای تعداد hop كمتری به شبكه مورد نظر باشد به عنوان بهترين مسير انتخاب خواهد شد. در واقع vector ، نشاندهنده مسير و يا جهت رسيدن به شبكه راه دور را مشخص می نمايد پروتكل های RIP و IGRP دو نمونه متداول از پروتكل های روتينگ Distance-vector می باشند. در اين پروتكل ها، تمامی اطلاعات جداول روتينگ برای روترهای همسايه كه مستقيما" متصل شده اند، ارسال می گردد.
• Link state : در پروتكل های روتينگ link-state كه به آنها پروتكل های shortest-path-first نيز گفته می شود، هر روتر سه جدول جداگانه را ايجاد می نمايد. يكی از اين جداول مسئوليت نگهداری اطلاعات مربوط به همسايگانی را برعهده دارد كه مستقيما" به روتر متصل شده اند، يكی ديگر حاوی توپولوژی تمامی شبكه است و در آخرين جدول، اطلاعات جدول روتينگ ذخيره می گردد. روترهائی كه با استفاده از پروتكل های link state پيكربندی شده اند نسبت به پروتكل های روتينگ Distance vector دارای اطلاعات بمراتب يشتری نسبت به شبكه می باشند. OSPF يكی از پروتكل های متداول در اين زمينه است. پروتكل های Link state اطلاعات بهنگام شامل وضعيت لينك های ارتباطی خود به ساير روترهای شبكه را ارسال می نمايند.
• Hybrid : اين نوع پروتكل ها از ويژگی دو پروتكل روتينگ Distance vector و Link state استفاده می نمايند. پروتكل EIGRP نمونه ای متداول در اين زمينه است.
• برای پيكربندی پروتكل های روتينگ در هر سازمان و يا موسسه تجاری نمی توان يك روش ثابت و خاص را پيشنهاد داد. در چنين حالاتی می بايست هر مورد را جداگانه بررسی و با توجه به شرايط موجود نسبت به انتخاب يكی از پروتكل های روتينگ اقدام نمود. در صورت آشنائی مطلوب با نحوه عملكرد پروتكل های مختلف روتينگ، می توان در خصوص انتخاب يك پروتكل روتينگ مناسب اقدام نمود.
پروتكل های روتينگ Distance-Vector نظير RIP و IGRP
الگوريتم های روتينگ Distance-Vector ، اطلاعات جداول روتينگ را بطور كامل برای روترهای همسايه ارسال تا آنها در ادامه اطلاعات دريافتی را با اطلاعات موجود در جداول روتينگ خود تركيب و دانش خود را در خصوص ارتباطات بين شبكه ای كامل نمايند. به روش فوق، روتينگ مبتنی بر شايعه ( rumor ) گفته می شود چراكه روتر، بهنگام سازی جدول روتينگ خود را بر اساس اطلاعات دريافتی از روتر همسايه انجام می دهد. در اين روش روتر به اطلاعات دريافتی در خصوص شبكه های راه دور اعتماد می نمايد بدون اين كه خود مستقيما" به اين نتايج رسيده باشد. همانگونه كه اشاره گرديد، RIP يك نمونه از پروتكل های روتينگ Distance-vector است كه برای تشخيص بهترين مسير به يك شبكه صرفا" از تعداد hop استفاده می نمايد. در صورتی كه RIP بيش از يك لينك را به يك شبكه مشابه و با تعداد hop برابر پيدا نمايد، بطور اتوماتيك از load balancing گردشی بر روی هر يك از لينك ها استفاده می نمايد. پروتكل RIP قادر به انجام load balancing بر روی حداكثر شش خط با cost يكسان است.
نحوه آغاز به كار يك پروتكل Distance-vector
برای آشنائی با پروتكل های روتينگ Distance-vector لازم است در ابتدا با نحوه عملكرد آنها پس از آغاز فعاليت آشنا شويم. در شكل زیر، وضعيت جدول روتينگ چهار روتر پس از راه اندازی نشان داده شده است. در جداول فوق صرفا اطلاعات مربوط به شبكه هائی كه مستقيما به هر يك از روترها متصل شده اند، ذخيره شده است. پس از آغاز به كار يك پروتكل روتينگ Distance-Vector بر روی هر يك از روترها، جداول روتينگ با استفاده از اطلاعات مسيرهای جمع آوری شده توسط هر يك از روترهای همسايه بهنگام می گردند.
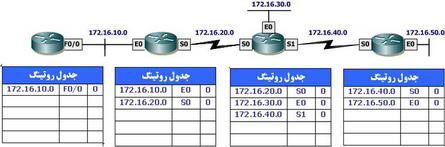
همانگونه كه در شكل فوق مشاهده می نمائيد، در هر يك از جداول روتينگ صرفا اطلاعات شبكه هائی كه مستقيما به هر روتر متصل شده اند، ذخيره شده است. هر روتر اطلاعات كامل جدول روتينگ خود را برای هر يك از اينترفيس های فعال ارسال می نمايد. جدول روتينگ هر روتر شامل اطلاعاتی نظير شماره شبكه، اينترفيس خروجی و تعداد hop به شبكه است. بدين ترتيب، اطلاعات جدول روتينگ كامل و هر يك از آنها دانش لازم در رابطه با تمامی شبكه های موجود در ارتباطات بين شبكه ای را كسب می نمايد. شكل زیر، وضعيت فوق را كه به آن همگرائی (converge) گفته می شود نشان می دهد. پس از همگرائی روترها، اطلاعات موجود در جداول روتينگ بين آنها ارسال نخواهد شد.
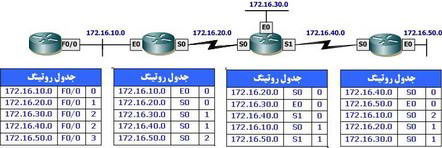
ايجاد همگرائی در شبكه
بديهی است مدت زمانی كه يك شبكه به همگرائی می رسد بسيار حائز اهميت بوده و كند بودن اين فرآيند می تواند پيامدهای نامطلوبی را برای شبكه به دنبال داشته باشد. يكی از مسائل در ارتباط با پروتكل RIP ، كند بودن زمان همگرائی آن است. جدول روتينگ در هر روتر اطلاعاتی راجع به شماره شبكه راه دور، اينترفيسی كه روتر از آن برای ارسال بسته های اطلاعاتی به شبكه استفاده می نمايد و تعداد hop و يا متريك به شبكه را نگهداری می نمايد.
حلقه های روتينگ ( Routing loops )
پروتكل های روتينگ Distance-Vector تغييرات ايجاد شده در ارتباطات بين شبكه ای را با انتشار مستمر اطلاعات بهنگام شده روتينگ به تمامی اينترفيس های فعال انجام می دهند. در اين فرآيند تمامی اطلاعات موجود در جدول روتينگ منتشر می گردد. فرآيند فوق علاوه بر اشغال بخشی از پهنای باند لينك ارتباطی، افزايش load پردازنده روتر را نيز به دنبال خواهد داشت. همچنين، در صورتی كه يك شبكه با مشكل مواجه شود، سرعت كند همگرائی پروتكل های روتينگ Distance-Vector می تواند پيامدهای منفی نظير جداول روتينگ متناقض و حلقه های روتينگ را به دنبال داشته باشد. در پروتكل های روتينگ Distance-Vector همواره احتمال ايجاد حلقه های روتينگ وجود خواهد داشت چراكه هر روتر بطور همزمان بهنگام نمی گردد. برای آشنائی با نحوه ايجاد حلقه های روتينگ يك نمونه مثال را در شكل زیر بررسی می نمائيم. فرض كنيد اينترفيس به شبكه شماره 5 با مشكل مواجه شود. تمامی روترها دانش خود را در رابطه با شبكه شماره 5 از طريق روتر E دريافت می نمايند. در جدول روتينگ روتر A يك مسير به شبكه شماره 5 از طريق روتر B وجود دارد.
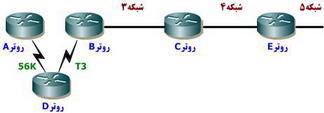
حلقه های روتينگ
زمانی كه شبكه شماره 5 دچار مشكل گردد، روتر E اين موضوع را به اطلاع روتر C می رساند. اين كار باعث می شود كه روتر C عمليات روتينگ به شبكه شماره 5 از طريق روتر E را متوقف نمايد. روترهای B، A و D نسبت به بروز مشكل برای شبكه شماره 5 آگاهی نداشته و همچنان اقدام به ارسال اطلاعات بهنگام می نمايند. سرانجام روتر C اطلاعات بهنگام شده خود را ارسال و باعث می گردد كه روتر B روتينگ به شبكه شماره 5 را متوقف نمايد. علی رغم اطلاع به روتر B ، روترهای A و D هنوز به دليل عدم دريافت اطلاعات بهنگام شده از اين موضوع آگاهی نداشته و از نظر آنها شبكه شماره 5 همچنان از طريق روتر B با متريك شماره 3 دردسترس است.
مشكل زمانی ايجاد می شود كه روتر A پيامی با اين موضوع را ارسال نمايد: " من همچنان اين جا هستم و اين ليست لينك هائی است كه من آنها را می شناسم " . در پيام فوق قابليت رسيدن به شبكه شماره 5 و نحوه دستيابی به آن تشريح شده است. بدين ترتيب روترهای B و D اخبار جالبی را دريافت می نمايند كه به آنها اعلام شده است شبكه شماره 5 از طريق روتر A قابل دستيابی است. روترهای فوق نيز اقدام به ارسال اطلاعاتی مبنی بر در دسترس بودن شبكه شماره 5 می نمايند. بدين ترتيب هر بسته اطلاعاتی كه مقصد آن شبكه شماره 5 باشد به روتر A و سپس به روتر B رسيده و مجددا به روتر A برگردانده می شود. بدين ترتيب يك "حلقه روتينگ " ايجاد می گردد كه برای پيشگيری و برخورد با آنها می بايست يك فكر اساسی كرد.
شمارش نامحدود
به "حلقه های روتينگ " كه در بخش قبل تشريح گرديد، " شمارش نامحدود " نيز گفته می شود و علت اصلی بروز اينچنين مسائلی، شايعات بیاساس و اطلاعات نادرستی است كه در شبكه توزيع شده است. بدون وجود يك سيستم كنترلی، تعداد hop هر مرتبه كه يك بسته اطلاعاتی از يك روتر عبور می يابد، افزايش خواهد يافت. سرعت كند همگرائی شبكه در الگوريتم های روتينگ يكی از دلايل اصلی بروز اينچنين مشكلاتی در شبكه است.
برای پيشگيری از اين نوع مسائل، راه حل های مختلفی در هر يك از پروتكل های روتينگ پياده سازی شده است. تعريف حداكثر تعداد hop ، روش route poising ، روش poison reverse و split horizon نمونه هائی در اين رابطه می باشند.
حداكثر تعداد hop
يكی از روش های حل مشكل "شمارش نامحدود " ، تعريف يك حداكثر برای تعداد hop است. پروتكل های روتينگ Distance-Vector نظير RIP صرفا امكان افزايش تعداد hop را تا 15 فراهم می نمايند. بنابراين هر چيزی كه نيازمند 16 hop باشد به منزله غيرقابل دسترس بودن تلقی می گردد. به عبارت ديگر، در مثال ارائه شده در بخش قبل، پس از ايجاد يك حلقه با پانزده hop ، اين موضوع به اثبات می رسد كه شبكه شماره 5 غيرفعال است. بنابراين شمارش حداكثر تعداد hop ، باعث پيشگيری از گرفتار شدن بسته های اطلاعاتی در حلقه های تكرار می گردد. روش فوق با اين كه راه حلی قابل اعمال در شبكه است ولی قادر به حذف حلقه های روتينگ در شبكه نمی باشد و بسته های اطلاعاتی همچنان در حلقه های روتينگ گرفتار خواهند شد. ولی در مقابل اين كه بسته های اطلاعاتی بدون نظارت، كنترل و بررسی در طول شبكه حركت كنند، حداكثر مسافتی را طی نموده ( به عنوان نمونه تا 16 hop ) و سپس از بين خواهند رفت.
Split Horizon
يكی ديگر از راه حل های برخورد با مشكل حلقه های روتينگ، Split Horizon است. در اين روش كه كاهش اطلاعات نادرست و حجم عملياتی اضافه روتينگ در يك شبكه Distance-Vector را به دنبال دارد از اين اصل تبعيت می شود كه اطلاعات نمی توانند در مسيری كه از طريق آن دريافت شده اند مجددا ارسال گردند. به عبارت ديگر، پروتكل روتينگ، اينترفيسی را كه از طريق آن بسته اطلاعاتی را دريافت كرده است بخاطر سپرده و هرگز از اينترفيس فوق برای ارسال مجدد آن استفاده نخواهد كرد. بدين ترتيب و با تبعيت از اصل فوق، روتر A از ارسال اطلاعات بهنگام شده ای كه از طريق روتر B دريافت نموده است برای روتر B منع می شود.
route poisoning
يكی ديگر از روش هائی كه باعث پيشگيری از اطلاعات بهنگام شده متناقض و توقف حلقه های روتينگ می گردد، route poisoning ناميده می شود. مثلا زمانی كه شبكه شماره 5 با مشكل مواجه می گردد، روتر E يك سطر را در جدول روتنيگ خود برای شبكه شماره 5 با مقدار hop شانزده ( غيرقابل دسترس بودن شبكه) درج می نمايد ( مقدار دهی اوليه route poisoning ). با نادرست اعلام كردن مسير رسيدن به شبكه شماره 5 ، روتر C از بهنگام سازی اطلاعات جدول روتينگ خود مبنی بر وجود يك مسير برای رسيدن به شبكه شماره 5 پيشگيری می نمايد. زمانی كه روتر C يك route poisoning را از طريق روتر E دريافت می نمايد، يك poison reverse را برای روتر E ارسال می نمايد تا اين اطمينان ايجاد گردد كه تمامی روترهای موجود در سگمنت اطلاعات مربوط به route poisoning را دريافت نموده اند. route poisoning و Split Horizon يك شبكه distance-vector با قابليت اطمينان و اعتماد بيشتر را ايجاد می نمايند كه در آن از بروز حلقه های تكرار پيشگيری می گردد.
Holddown
با استفاده از holddown پيشگيری لازم در خصوص بهنگام سازی اطلاعات يك مسير بی ثبات انجام می شود. اين وضعيت معمولا بر روی يك لينك سريال اتفاق می افتد كه در يك لحظه برقرار و در لحظه ای ديگر غيرفعال می گردد (flapping ). در صورت عدم استفاده از روشی جهت تثبيت اين وضعيت، شبكه هرگز همگراء نشده و اينترفيسی كه دائما up و down می گردد می تواند تمامی شبكه را با مشكل مواجه سازد.
با استفاده از holddown از ثبت مسيرهائی كه وضعيت آنها با سرعت زياد تغيير پيدا می نمايد، پيشگيری بعمل آمده و به آنها يك فرصت زمانی داده می شود تا وضعيت پايداری پيدا نمايند. بدين ترتيب، به روترها اعلام می شود كه برای يك بازه زمانی خاص هر گونه تغييراتی كه بر روی مسيرهای حذف شده اخير تاثير می گذارد را محدود نمايند. با اين كار از درج مسيرهای بی ثبات در ساير جداول روتينگ پيشگيری بعمل می آيد.
زمانی كه يك روتر اطلاعات بهنگام شده ای را از طريق يكی از همسايگان مبنی بر غيرقابل دسترس بودن يك شبكه دريافت می نمايد ( شبكه ای كه تا پيش از اين فعال بوده است )، تايمر holddown آغاز به كار می كند. در صورتی كه اطلاعات بهنگام شده جديدی از يك همسايه دريافت شود كه دارای متريك بهتری نسبت به وضعيت اوليه موجود در جدول روتينگ باشد، holddown برداشته شده و داده عبور داده می شود ولی اگر اطلاعات بهنگام شده ای از يك روتر همسايه دريافت گردد ( قبل از اتمام مدت زمان تايمر holddown )، كه دارای متريك برابر و يا كمتر از مسير قبلی باشد، از اطلاعات جديد بهنگام صرفنظر و تايمر به فعاليت خود ادامه خواهد داد.
بدين ترتيب زمان بيشتری برای ايجاد ثبات در شبكه قبل از آغاز فرآيند همگرائی آن فراهم می گردد. holddown از فرآيند بهنگام سازی مبتنی بر trigger استفاده می نمايد. در اين فرآيند تايمر reset می گردد تا به روترهای همسايه اطلاع داده شود يك تغيير در شبكه اتفاق افتاده است. برخلاف پيام های بهنگام از روترهای همسايه، در اين نوع بهنگام سازی ( مبتنی بر trigger ) يك جدول روتينگ جديد ايجاد و بلافاصله برای روترهای همسايه ارسال می گردد چراكه يك تغيير در ارتباطات بين شبكه ای تشخيص داده شده است.
پروتكل RIP
RIP ( برگرفته شده از Routing Information Protocol ) به معنی واقعی يك پروتكل distance-vector است. پروتكل فوق در هر 30 ثانيه تمام اطلاعات موجود در جدول روتينگ را برای تمامی اينترفيس های فعال ارسال می نمايد. RIP صرفا از تعداد hop برای تعيين بهترين مسير به شبكه راه دور استفاده می نمايد. .حداكثر تعداد hop می تواند عدد 15 را داشته باشد و نسبت دهی عددی بالاتر از 15 به منزله غيرقابل دسترس بودن شبكه است. RIP در شبكه های كوچك به خوبی كار می كند ولی برای شبكه های بزرگ كه دارای لينك های ارتباطی WAN ( برگرفته شده از wide area network ) كند و تعداد بسيار زيادی روتر هستند مناسب نمی باشد. در نسخه شماره يك RIP صرفا از روتينگ classful استفاده می گردد. اين بدان معنی است كه تمامی دستگاه های موجود در شبكه می بايست از subnet mask مشابهی استفاده نمايند. محدوديت فوق به دليل ماهيت ارسال اطلاعات بهنگام می باشد. در نسخه شماره يك RIP ، اطلاعات بهنگام ارسالی شامل اطلاعات subnet mask نمی باشند. در RIP نسخه دو، ويژگی جديدی به نام روتينگ Prefix ارائه شده است كه به كمك آن امكان ارسال اطلاعات subnet mask به همراه مسيرهای بهنگام شده فراهم می گردد. به اين نوع روتينگ، اصطلاحا روتينگ classless گفته می شود.
RIP از سه نوع تايمر مختلف برای تنظيم كارآئی خود استفاده می نمايد.
• Route update timer ، فاصله زمانی ارسال يك نسخه كامل از اطلاعات بهنگام روتينگ را مشخص می نمايد. در بازه زمانی فوق، روتر يك نسخه كامل از اطلاعات موجود در جدول روتينگ خود را برای تمامی همسايگان ارسال می نمايد. اين زمان معمولا 30 ثانيه در نظر گرفته می شود.
• Route invalid timer ، مدت زمانی را مشخص می نمايد كه پس از سپری شدن آن، روتر به اين نتيجه خواهيد رسيد كه يك مسير غيرمعتبر است. اين زمان معمولا 180 ثانيه در نظر گرفته می شود و اگر يك روتر در بازه زمانی فوق هيچگونه اطلاعات جديدی را در خصوص يك مسير خاص دريافت ننمايد، آن مسير را غيرمعتبر می نمايد. در صورت تحقق چنين شرايطی، روتر اقدام به ارسال اطلاعات بهنگام برای تمامی همسايگان خود می نمايد تا به آنها بگويد كه مسير غيرمعتبر است.
• Route flush timer ، مدت زمان بين غيرمعتبر اعلام شدن يك مسير و حذف آن از جدول روتينگ را مشخص می نمايد. اين زمان معمولا 240 ثانيه در نظر گرفته می شود. قبل از اين كه يك مسير از جدول روتينگ حذف گردد، روتر اين موضوع را به اطلاع همسايگان خود می رساند. مقدار Route invalid timer می بايست كمتر از route flush timer باشد تا روتر زمان كافی جهت اطلاع به همسايگان خود را قبل از بهنگام سازی جدول در اختيار داشته باشد.
پروتكل IGRP
IGRP ( برگرفته شده از Interior Gateway Routing Protocol ) يكی از پروتكل روتينگ distance-vector طراحی شده توسط شركت سيسكو است. اين بدان معنی است در صورت استفاده از پروتكل فوق در يك شبكه، می بايست تمامی روترها از نوع سيسكو باشند. شركت سيسكو هدف از ايجاد پروتكل IGRP را غلبه بر برخی محدوديت های پروتكل RIP عنوان كرده است. IGRP می تواند حداكثر دارای 255 ، hop باشد كه مقدار پيش فرض آن 100 در نظر گرفته می شود. اين وضعيت در شبكه های بزرگ بسيار مفيد است و مشكل داشتن حداكثر 15 hop در يك شبكه مبتنی بر پروتكل RIP را برطرف نمايد.
IGRP از يك روش متفاوت نسبت به RIP جهت محاسبه متريك استفاده می كند. در اين پروتكل، بطور پيش فرض از پهنای باند و تاخير خط به عنوان شاخص هائی جهت تعيين بهترين مسير استفاده می گردد. به فرآيند فوق متريك تركيبی ( composite metric ) گفته می شود. همچنين برای محاسبه متريك از شاخص هائی ديگر نظير قابليت اعتماد، ميزان load و MTU ( برگرفته شده از maximum transmission unit ) استفاده می گردد ( از شاخص های اشاره شده بطور پيش فرض در محاسبه متريك استفاده نمی گردد ) .
پروتكل IGRP با RIP دارای تفاوت های عمده ای است كه به برخی از آنها اشاره می گردد:
• امكان استفاده از IGRP در شبكه های بزرگ
• IGRP برای فعال شدن از يك AS number (برگرفته شده از autonomous system ) استفاده می نمايد.
• IGRP در هر 90 ثانيه يك مرتبه بهنگام سازی جدول روتينگ را بطور كامل انجام می دهد.
• IGRP از پهنای باند و تاخير خط به عنوان يك متريك استفاده می نمايد.
برای كنترل كارآئی، پروتكل IGRP از تايمرهای مختلف زير با مقادير پيش فرض استفاده می نمايد:
• Update timers ، فركانس ارسال پيام های بهنگام روتينگ را مشخص می نمايد. مقدار پيش فرض 90 ثانيه در نظر گرفته شده است.
• Invalid timers ، مدت زمانی را كه يك روتر می بايست منتظر بماند قبل از اين كه يك مسير نادرست را به ديگران اعلام نمايد ( در صورتی كه در بازه زمانی مورد نظر يك بهنگام جديد دريافت نگردد )، مشخص می نمايد. مقدار پيش فرض سه برابر زمان Update timer است.
• Holddown timers ، مدت زمان holddown را مشخص می نمايد. مقدار پيش فرض سه برابر زمان Update timer به اضافه 10 ثانيه در نظر گرفته شده است.
• Flush timers، مشخص می نمايد كه چه مدت زمانی می بايست سپری شود قبل از اين كه بتوان يك مسير را از جدول روتينگ حذف كرد. مقدار پيش فرض هفت برابر زمان Update timer در نظر گرفته می شود. در صورتی كه مقدار Update timer برابر با 90 ثانيه در نظر گرفته شود، 360 ثانيه طول خواهد كشيد تا بتوان يك مسير را از جدول روتينگ حذف كرد.
پروتكل های روتينگ تركيبی و يا EIGRP
EIGRP ( برگرفته شده از Enhanced IGRP ) يك پروتكل distance-vector و classless است كه امكانات بيشتری را نسبت به IGRP ارائه می نمايد. همانند IGRP ، پروتكل EIGRP از مفهوم يك ناحيه خودمختار برای تشريح مجموعه ای از روترهای همجوار كه پروتكل های روتينگ مشابهی را اجراء و اطلاعات روتينگ را به اشتراك می گذارند، استفاده می نمايد. برخلاف IGRP ، پروتكل EIGRP در مسيرهای بهنگام خود از Subnet mask استفاده می نمايد. همانگونه كه اطلاع داريد، ارائه اطلاعات subnet امكان استفاده از VLSM ( برگرفته شد ه از Variable Length Subnet Masking ) و خلاصه سازی را در زمان طراحی شبكه فر اهم می نمايد. در برخی موارد به پروتكل EIGRP به عنوان يك پروتكل تركيبی روتينگ نيز اشاره می شود چراكه دارای ويژگی هائی از پروتكل های distance-vector و link-state می باشد. مثلا EIGRP اقدام به ارسال بسته های اطلاعاتی link-state همانند OSPF ( برگرفته شده از Open Shortest Path First ) نمی كند. در مقابل، EIGRP داده بهنگام distance-vector شامل اطلاعاتی در رابطه با شبكه ها به اضافه هزينه رسيدن به آنها را از ديدگاه روتر پيشنهاد دهنده ارسال می نمايد. همچنين، پروتكل EIGRP دارای خصايص Link-state است. يكسان سازی جداول روتينگ بين همسايگان در زمان راه اندازی و ارسال اطلاعات بهنگام جديد و خاص در زمان بروز تغييرات در توپولوژی شبكه، نمونه ای در اين زمينه می باشد.
وجود برخی ويژگی های قدرتمند در پروتكل EIGRP آن را از IGRP و ساير پروتكل های روتينگ كاملا متمايز می نمايد.
• حمايت از IP ، IPX و AppelTalk از طريق PDM ( برگرفته شده از Protocol-Dependent Modules )
• ارتباط از طريق RTP ( برگرفته شده از Reliable Transport Protocol )
• انتخاب بهترين مسير از طريق DUAL (برگرفته شده از diffusing update algorithm )
• حمايت از چندين سيستم خودمختار ( AS )
• حمايت از خلاصه سازی و VLSM ( برگرفته شده از Variable Length Subnet Masking )
ماژول های وابسته به پروتكل (Protocol-Dependent Modules)
يكی از ويژگی های جالب پروتكل EIGRP ، حمايت آن از روتينگ چندين پروتكل لايه شبكه نظير IPX ، IP و AppelTalk است. پروتكل IS-IS ( برگرفته شده از Intermediate System-to-Intermediate System ) تنها پروتكل روتينگ نزديك به پروتكل EIGRP است كه از چندين پروتكل لايه شبكه حمايت می نمايد. با اين تفاوت كه پروتكل فوق صرفا از IP و CLNS ( برگرفته شده از Connectionless Network Service) حمايت می نمايد. EIGRP با بكارگيری پتانسيلی با نام PDM ( برگرفته شده از protocol-dependent modules ) از پروتكل های مختلف لايه شبكه حمايت می نمايد. هر PDM پروتكل EIGRP ، مجموعه ای جداگانه از جداول حاوی اطلاعات روتينگ را نگهداری می نمايد كه در ارتباط با يك پروتكل خاص بكارگرفته می شوند. اين بدان معنی است كه EIGRP برای هر يك از پروتكل ها يك جدول جداگانه را نگهداری می نمايد ( نظير جداول IP/EIGRP ، IPX/EIGRP و AppelTalk/EIGRP ).
تشخيص همسايگان
قبل از اين كه روترهای EIGRP تصميم به مبادله مسيرها با يكديگر نمايند، می بايست همسايگان خود را شناسائی نمايند. برای ايجاد رابطه همسايگی می بايست شرايط زير وجود داشته باشد:
• دريافت Hello و يا ACK ( برگرفته شده از acknowledgment )
• تطبيق شماره سيستم خودمختار (AS)
• متريك يكسان
پروتكل های Link-state علاقه مند به استفاده از پيام های Hello برای ايجاد رابطه همسايگی می باشند چراكه آنها معمولا اقدام به ارسال اطلاعات بهنگام مسيرها بطور ادواری نمی نمايند و می بايست با بكارگيری مكانيزم هائی خاص قادر به تشخيص همسايگان خود بطور پويا ( تشخيص يك همسايه جديد و يا خروج از ليست همسايگان ) باشند. برای برقراری رابطه همسايگی، روترهای EIGRP می بايست بطور پيوسته پيام هائی موسوم به Hello را از همسايگان خود دريافت نمايند.
روترهای EIGRP كه به نواحی خودمختار (AS ) مختلفی وابسته می باشند بطور اتوماتيك اطلاعات روتينگ را بين خود به اشتراك نمی گذارند و به عنوان همسايه تلقی نمی گردند. سياست فوق مزايای متعددی را به دنبال خواهد داشت ( خصوصا زمانی كه از پروتكل EIGRP در شبكه های بزرگ استفاده می گردد ). در چنين مواردی، حجم اطلاعات روتينگ منتشر شده در بين يك ناحيه خود مختار خاص كاهش پيدا می نمايد. تنها نكته قابل تامل در اين رابطه، لزوم توزيع مجدد بين نواحی خود مختار بطور دستی است.
زمانی كه EIGRP يك همسايه جديد را تشخيص می دهد و قصد ايجاد يك رابطه همسايگی با آن را از طريق مبادله پيام های Hello دارد، تمامی اطلاعات روتينگ خود را در اختيار آن قرار می دهد ( تنها حالتی كه تمامی اطلاعات جدول روتينگ ارسال می گردد ).
زمانی كه اين اتفاق می افتد، هر يك از آنها تمامی جداول روتينگ خود را برای ديگری منتشر می نمايد. پس از اين كه هر يك از آنها از مسيرهای همسايه خود آگاهی يافت، صرفا تغييرات در جدول روتينگ بين آنها مبادله می گردد. زمانی كه روترهای EIGRP اطلاعات بهنگام را از همسايگان خود دريافت می نمايند، آنها را در يك جدول توپولوژی محلی ذخيره می نمايند. اين جدول حاوی تمامی مسيرهای شناخته شده از تمامی همسايگان شناخته شده است و از آن به عنوان مواد خام انتخاب بهترين مسير و استقرار آن در جدول روتينگ استفاده می گردد.
ارتباط از طريق RTP
EIGRP از يك پروتكل اختصاصی با نام RTP ( برگرفته شده از Reliable Transport Protocol ) به منظور مديريت مبادله پيام بين روترهائی كه بر اساس EIGRP با يكديگر گفتگو می كنند، استفاده می نمايد.
يكی از ويژگی های مهم پروتكل RTP ، قابليت اطمينان به آن است. شركت سيسكو مكانيزمی را طراحی نموده است كه به كمك آن بتواند پيام های multicast و unicast بهنگام سازی را با سرعت توزيع و وضعيت دريافت داده توسط گيرنده را پيگيری نمايد. زمانی كه EIGRP ترافيك multicast را ارسال می نمايد از آدرس 0 . 0. 0 . 224 كلاس D استفاده می نمايد. همانگونه كه اشاره گرديد هر روتر EIGRP نسبت به همسايگان خود آگاهی داشته و برای هر پيام multicast كه ارسال می نمايد، ليستی از همسايگان را كه به آن پاسخ می دهند نگهداری می نمايد. در صورتی كه EIGRP پاسخی را از يك همسايه دريافت نكند، در تلاشی مجدد برای آن يك پيام unicast را ارسال می نمايد. در صورتی كه پس از 16 مرتبه تلاش پاسخی از همسايه دريافت نگردد، اين فرضيه به اثبات می رسد كه همسايه از بين رفته است. به فرآيند فوق reliable multicast گفته می شود.
روترها برای رهگيری اطلاعات ارسالی خود به آنها يك شماره ترتيب را نسبت می دهند. با استفاده از روش فوق، امكان تشخيص اطلاعات قديمی، تكراری و يا خارج از ترتيب فراهم می گردد. قابليت انجام اين گونه عمليات بسيار حائز اهميت است چراكه EIGRP يك پروتكل آرام است كه در زمان راه اندازی، بانك های اطلاعاتی روتينگ خود را با همسايگان مبادله و در ادامه و به منظور حفظ سازگاری بانك اطلاعاتی در طول زمان، صرفا اقدام به مبادله تغييرات می نمايد. از دست دادن دائمی هر گونه بسته اطلاعاتی و يا پردازش بر روی بسته های اطلاعاتی بيهوده می تواند خرابی بانك اطلاعاتی روتينگ را به دنبال داشته باشد.
استفاده از الگوريتم DUAL برای انتخاب بهترين مسير
EIGRP از الگوريتم DUAL (برگرفته شده از diffusing update algorithm ) برای انتخاب و نگهداری بهترين مسير به هر شبكه راه دور استفاده می نمايد. الگوريتم فوق دارای ويژگی های زير است:
• backup از مسيرها
• حمايت از VLSMs
• بازيافت پويای مسير
• درخواست از همسايگان برای گزينش مسيرهای ناشناخته ديگر
• ارسال درخواست برای يك مسير جايگزين در صورت عدم يافتن مسير
EIGRP با بكارگيری الگوريتم DUAL توانسته است سريعترين زمان همگرائی در بين ساير پروتكل های روتينگ را دارا باشد. سرعت همگرائی بالای EIGRP به دو عامل اساسی زير بستگی دارد:
• عامل اول: روترهای EIGRP يك نسخه از تمامی مسيرهای همسايگان خود را نگهداری می نمايند تا بتوانند از آن برای محاسبه cost هر شبكه راه دور استفاده نمايند. در صورت بروز مشكل برای بهترين مسير، محتويات جدول توپولوژی به منظور انتخاب بهترين مسير جايگرين بررسی می گردد.
• عامل دوم: در صورتی كه يك مسير جايگزين مناسب در جدول محلی توپولوژی وجود نداشته باشد، روترهای EIGRP به سرعت از همسايگان خود برای يافتن يك مسير مناسب درخواست كمك می نمايند.
همانگونه كه اشاره گرديد، ايده ارسال پيام های Hello ، تشخيص سريع همسايگان جديد و همسايگانی خارج شده از ليست همسايگان است. RTP ، مكانيزمی مطمئن برای حمل پيام ها را ارائه می نمايد و DUAL با استناد به مكانيزم فوق، مسئوليت انتخاب و نگهداری اطلاعات در رابطه با بهترين مسيرها را برعهده دارد.
چندين ناحيه خودمختار
EIGRP از شماره نواحی خود مختار ( ASNs ) برای شناسائی مجموعه ای از روترهائی كه اطلاعات روتينگ را بين خود به اشتراك می گذارند= ، استفاده می نمايد. صرفا روترهائی كه دارای ASN ( برگرفته شده از autonomous system numbers ) مشابه می باشند، مسيرها را به اشتراك می گذارند. با استفاده از رويكرد فوق در شبكه های بزرگ، به معظل جداول مسير و توپولوژی پيچيده كه كاهش سرعت همگرائی شبكه را به دنبال خواهد داشت، خاتمه داده می شود. با تقسيم شبكه به چندين ناحيه خودمختار جداگانه EIGRP ، درصد بسيار زيادی از تبعات منفی مديريت و نگهداری يك شبكه بزرگ كاهش می يابد. هر ناحيه خود مختار شامل مجموعه ای از روترهای همجوار است كه اطلاعات مسيرها را بين خود به اشتراك گذاشته و با توزيع مجدد آنها زمنيه استفاده از اطلاعات فوق بين نواحی خودمختار جداگانه نيز فراهم می گردد.
استفاده از توزيع مجدد در EIGRP ، بيانگر يك ويژگی جالب ديگر از اين پروتكل است. معمولا AD ( برگرفته شده از administrative distance ) مسيرهای EIGRP معادل 90 در نظر گرفته می شود. اين موضوع صرفا برای مسيرهائی كه از آنها به عنوان مسيرهای داخلی EIGRP نام برده می شود صادق می باشد. اين گونه مسيرها، مسيرهائی هستند كه از درون يك ناحيه خودمختار خاص و توسط روترهای EIGRP كه جملگی عضو يك سيستم خود مختار مشابه می باشند، سرچشمه می گيرند. مسيرهای خارجی EIGRP ، نوع ديگری از مسيرها می باشند كه دارای AD معادل 170 می باشند كه خيلی هم خوب نيست. اين گونه مسيرها، در جداول مسير EIGRP بطور دستی و يا توزيع مجدد اتوماتيك قرار می گيرند و شبكه هائی را مشخص می نمايند كه در خارج از سيستم خود مختار EIGRP می باشند.
حمايت از VLSMs و خلاصه سازی
EIGRP به عنوان يكی از پروتكل های روتينگ classless ، از VLSMs حمايت می نمايد. حمايت از ويژگی VLSM بسيار حائز اهميت است چراكه با استفاده از پتانسيل فوق امكان نگهداری فضای آدرس دهی از طريق subnet mask فراهم می گردد ( نظير استفاده از 30 بيت subnet mask برای شبكه های point-to-point ).
با توجه به اين كه subnet mask به همراه هر مسير بهنگام نيز ارسال می گردد، اين امكان برای پروتكل EIGRP فراهم می گردد كه از زير شبكه های ناپيوسته نيز حمايت نمايد. بدين ترتيب، طراحان شبكه های كامپيوتری در زمان طراحی يك شبكه IP دارای انعطاف بيشتری می باشند.
يك شبكه ناپيوسته دارای دو شبكه classful است كه از طريق يك شبكه با كلاس متفاوت به يكديگر متصل شده اند. شكل زیر، يك شبكه ناپيوسته را نشان می دهد.

شبكه ناپيوسته
در شكل فوق دو زير شبكه به آدرس های 0 . 10 . 16 . 172 و 0 . 20 . 16 . 172 از طريق يك شبكه 0 . 1 . 3 . 10 به يكديگر متصل شده اند. هر روتر اين گونه فكر می كند كه دارای تمامی شبكه كلاس B با آدرس 0 . 0. 16 . 172 و به صورت پيش فرض است. EIGRP ، همچنين از ايجاد دستی خلاصه ها بر روی هر روتر EIGRP حمايت می نمايد. اين كار كاهش اندازه جدول مسير را به دنبال خواهد داشت. EIGRP ، بطور اتوماتيك شبكه ها را در محدوده های classful مربوطه خلاصه می نمايد.
پروتكل های روتينگ link state نظير OSPF
در پروتكل های link-state كه به آنها پروتكل های shortest path first نيز گفته می شود، هر روتر سه جدول جداگانه را ايجاد می نمايد. يكی از اين جداول وضعيت همسايگانی را كه مستقيما به آن متصل شده اند در خود نگهداری می نمايد. در جدول ديگر، توپولوژی تمامی شبكه نگهداری می گردد و از جدول سوم برای نگهداری اطلاعات روتينگ استفاده می شود. روترهای link-state نسبت به پروتكل های روتينگ distance-vector دارای اطلاعات بيشتری در ارتباط با شبكه و ارتباطات بين شبكه ای می باشند. پروتكل های link-state اطلاعات بهنگام خود را برای ساير روترهای موجود در شبكه ارسال می نمايند (وضعيت لينك).
OSPF ( برگرفته شده از Open Shortest Path First ) يك پروتكل روتينگ IP است كه دارای تمامی ويژگی های يك پروتكل link-state است. پروتكل فوق، يك پروتكل روتينگ استاندارد باز است كه توسط مجموعه ای از توليدكنندگان شبكه از جمله شركت سيسكو ايجاد شده است. در صورتی كه در يك شبكه از روترهائی استفاده می گردد كه تمامی آنها متعلق به شركت سيسكو نمی باشند، نمی توان از پروتكل EIGRP استفاده كرد. در چنين مواردی می توان از گزينه هائی ديگر نظير RIP ، RIPv2 و يا OSPF استفاده نمود. در صورتی كه ابعاد يك شبكه بسيار بزرك باشد، تنها گزينه موجود پروتكل OSPF و يا استفاده از route redistribution است ( يك سرويس ترجمه بين پروتكل های روتينگ ).OSPF ، با استفاده از الگوريتم Dijkstra كار می كند. در ابتدا، اولين درخت كوتاهترين مسير ايجاد می گردد و در ادامه جدول روتينگ از طريق بهترين مسيرها توزيع می گردد. اين پروتكل دارای سرعت همگرائی بالائی است ( شايد به اندازه سرعت همگرائی EIGRP نباشد ) و از چندين مسير با cost يكسان به مقصد مشابه حمايت می نمايد. برخلاف EIGRP ، پروتكل OSPF صرفا از روتينگ IP حمايت می نمايد. در بحث مربوط به پروتكل های link-state ، اكثر علاقه مندان به دريافت مدرك CCNA، در آغاز با پروتكل OSPF آشنا می شوند. بدين منظور اين پروتكل با پروتكل های سنتی distance-vector نظير RIPv1 مقايسه و ماحصل آن در جدول زیر نشان داده شده است.
|
OSPF
|
RIPv1
|
ويژگی
|
|
Link-state
|
Distance-vector
|
نوع پروتكل
|
|
بلی
|
خير
|
حمايت از classless
|
|
بلی
|
خير
|
حمايت از VLSM
|
|
خير
|
بلی
|
خلاصه سازی اتوماتيك
|
|
بلی
|
خير
|
خلاصه سازی دستی
|
|
ارسال multicast
در صورت بروز تغييرات
|
ارسال متناوب
broadcast
|
انتشار مسير
|
|
پهنای باند
|
hops
|
متريك مسير
|
|
ندارد
|
15
|
محدوديت تعداد hop
|
|
سريع
|
كند
|
همگرائی
|
|
بلی
|
خير
|
Peer authentication
|
|
بلی ( استفاده از نواحی)
|
خير ( فقط flat)
|
شبكه سلسله مراتبی
|
|
Dijkstra
|
Bellman-Ford
|
الگوريتم محاسبه مسير
|
OSPF دارای ويژگی های متعددی است كه صرفا تعداد اندكی از آنها در جدول فوق نشان داده شده است. تمامی شواهد موجود نشان دهنده اين واقعيت است كه پروتكل OSPF يك پروتكل سريع، قابل توسعه و مستحكم است كه می توان از آن در هزاران شبكه عملياتی استفاده كرد. OSPF بگونه ای طراحی شده است كه بتواند از شبكه های سلسله مراتبی حمايت نمايد. با بكارگيری ويژگی فوق می توان ارتباطات بين شبكه ای بزرگ را به چندين شبكه كوچكتر كه به آنها ناحيه گفته می شود، تقسيم نمود.
بكارگيری پتانسيل فوق مزايای متعددی را به دنبال خواهد داشت:
• كاهش اضافه عمليات روتينگ
• افزايش سرعت همگرائی
• محدود كردن بی ثباتی شبكه در يك ناحيه و عدم اشاعه آن به ساير نواحی شبكه
OSPF ، درون يك ناحيه خودمختار ( AS ) اجراء می شود ولی اين امكان نيز وجود دارد كه از آن برای اتصال چندين ناحيه خودمختار به يكديگر استفاده كرد. به روترهائی كه نواحی خود مختار را به يكديگر متصل می نمايند، ASBR ( برگرفته شده از autonomous system boundary router ) گفته می شود. فلسفه ايجاد نواحی خود مختار، كاهش زمان بهنگام سازی و عدم انتشار مشكلات ايجاد شده در يك ناحيه خاص به ساير نواحی شبكه است.
VLAN و سوئيچ
سوئيچ های لايه دو فريم ها را صرفا برای فيلترينگ می خوانند ( كاری با پروتكل لايه شبكه ندارند). همچنين، به صورت پيش فرض، سوئيچ ها تمامی broadcast را فوروارد می نمايند ولی با ايجاد و پياده سازی VLAN ، عملا broadcast domain كوچك تر در لايه دو بوجود خواهد آمد. اين بدان معنی است كه broadcast ارسالی از يك گره يك VLAN، برای پورت های پيكربندی شده در VLAN متفاوت ديگر ارسال نخواهد شد.
بنابراين با نسبت دهی پورت های سوئيچ و يا كاربران به گروه های VLAN بر روی يك سوئيچ و يا گروهی از سوئيچ های متصل شده به هم ( switch fabric )، انعطاف لازم برای اضافه كردن كاربرانی كه قصد داريم آنها را به broadcast domain مورد نظر صرفنظر از مكان فيزيكی ملحق نمائيم، فراهم می گردد. با استفاده از روش فوق می توان broadcast ارسالی از يك كارت شبكه معيوب در تمامی شبكه را بلاك كرد. يكی ديگر از مزايای بخش بندی با استفاده از VLAN ، زمانی است كه اندازه يك VLAN بسيار بزرگ شده باشد. در چنين مواردی می توان چندين VLAN را ايجاد كرد تا پيشگيری لازم در خصوص استفاده بيش از حد از پهنای باند موجود صورت پذيرد ( هر اندازه كاربران كمتری بر روی يك VLAN باشند، تعداد كمتری متاثر از broadcast خواهند شد ). در چنين مواردی لازم است در زمان ايجاد VLAN به اين موضوع نيز دقت شود كه چه سرويس هائی بر روی شبكه فعال است و كاربران با اين سرويس ها چگونه ارتباط برقرار می نمايند.
مثال : بررسی يك نمونه شبكه فرضی بدون استفاده از VLAN و سوئيچ
برای آشنائی با نحوه عملكرد يك VLAN به همراه يك سوئيچ، در ادامه يك شبكه سنتی را بررسی خواهيم كرد. در شكل زیر، نحوه ايجاد يك شبكه با اتصال چندين شبكه محلی فيزيكی با استفاده از هاب و روتر نشان داده شده است.
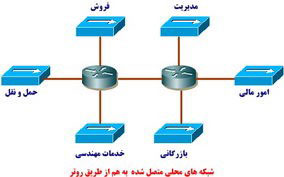
شبكه های محلی متصل شده به هم از طريق روتر
در شكل فوق، هر شبكه با استفاده از يك پورت هاب به روتر متصل شده است ( هر سگمنت دارای شماره شبكه منطقی مختص به خود است، گرچه اين موضوع در شكل نشان داده نشده است). هر گره متصل شده به يك شبكه فيزيكی خاص، می بايست در زمان برقراری ارتباط بر روی شبكه از شماره شبكه خود استفاده نمايد.
توجه داشته باشيد كه هر دپارتمان دارای شبكه اختصاصی مختص به خود است، بنابراين در صورتی كه لازم است كاربران جديدی را به عنوان نمونه به دپارتمان فروش اضافه نمائيم، كافی است آنها را به شبكه محلی مربوط به دپارتمان فروش متصل نمود. در ادامه، كاربران جديد بطور اتوماتيك به عنوان بخشی از collision و broadcast domain دپارتمان فروش محسوب خواهند شد. از اين نوع طراحی طی چندين سال در سازمان ها و موسسات استفاده می گرديد. سيستم فوق دارای اشكالات اساسی متعددی است:
• در صورتی كه ظرفيت پورت های دپارتمان فروش تكميل گردد و قصد داشته باشيم كاربر و يا كاربران جديدی را دپارتمان فوق اضافه نمائيم، چه كار می بايست كرد؟
• در صورتی كه دپارتمان فروش چندين كارمند جديد را استخدام كرده باشد و دپارتمان فوق به دليل كمبود مكان فيزيكی اجازه استقرار كارمندان جديد را نداشته باشد، چگونه می توان كارمندان فوق را به شبكه دپارتمان فروش متصل كرد؟
فرض كنيد، دپارتمان امور مالی دارای مكان های آزاد متعددی است كه می توان كارمندان جديد بخش فروش را در آنجا مستقر كرد تا امكان اتصال آنها به شبكه فراهم گردد. با اتصال كاربران فوق به شبكه، عملا آنها به عنوان بخشی از شبكه امور مالی در نظر گرفته خواهند شد. اين موضوع به دلايل متعددی قابل قبول نيست. از همه مهمتر مسائل امنيتی است. چراكه در چنين وضعيتی كاربران جديد به عنوان عضوی از broadcast domain بخش امور مالی در نظر گرفته شده و می توانند تمامی سرويس دهندگان و سرويس های شبكه موجود بر روی شبكه دپارتمان امور مالی را مشاهده نمايند. در چنين مواردی، كاربران بخش فروش كه از طريق شبكه امور مالی به شبكه متصل شده اند، جهت دستيابی به سرويس های شبكه فروش می بايست از طريق روتر به سرويس دهنده بخش فروش login نمايند ( عدم وجود كارآئی مطلوب ).
مثال : بررسی يك نمونه شبكه فرضی با استفاده از VLAN و سوئيچ
در اين بخش به بررسی شبكه ای خواهيم پرداخت كه در آن از سوئيچ استفاده شده است. شكل زیر، اين موضوع را به اثبات می رساند كه چگونه سوئيچ قادر است محدوده های فيزيكی را به منظور حل مشكلات اشاره شده در بخش قبل برطرف نمايد.
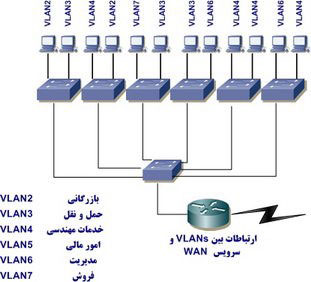
پياده سازی Vlans به كمك سوئيچ
برای ايجاد يك broadcast domain جهت هر دپارتمان، از شش VLAN (شماره دو تا هفت ) استفاده شده است. به هر يك از پورت های سوئيچ يك شماره عضويت VLAN نسبت داده شده است ( با توجه به هاست و اين كه در كدام broadcast domain می بايست مستقر گردد ). با توجه به طراحی فوق، اگر قرار باشد كه يك كاربر جديد را به VLAN دپارتمان فروش ( VLAN شماره هفت ) اضافه نمائيم، می توان صرفا پورت مورد نياز به VLAN شماره هفت را به آن نسبت داد، صرفنظر از اين كارمند بخش فروش از لحاظ فيزيكی در چه مكانی مستقر است. وضعيت فوق يكی از مزايای مهم طراحی شبكه با استفاده از VLAN نسبت به طراحی در مدل های قبلی را نشان می دهد. بدين ترتيب، می توان به سادگی هر هاستی را كه لازم است در VLAN دپارتمان فروش قرار گيرد، به VLAN شماره هفت نسبت داد. توجه داشته باشيد كه شماره گذاری VLAN از عدد دو شروع شده است. شايد برای شما اين سوال مطرح شده باشد كه چه بلائی بر سر VLAN شماره يك آمده است. اين VLAN يك VALN مديريتی است و علی رغم اين كه می توان از آن برای يك workgroup استفاده كرد ولی كاربرد آن صرفا برای اهداف مديريتی است. شما نمی توانيد نام VLAN 1 را حذف و يا تغيير دهيد و به صورت پيش فرض تمامی پورت های موجود بر روی سوئيچ عضوی از VLAN 1 می باشند تا زمانی كه آنها را تغيير دهيد. هر VLAN به منزله يك broadcast domain تلقی می گردد، بنابراين می بايست دارای subnet number مختص به خود باشد. همانگونه كه در شكل فوق نشان داده شده است. در صورتی كه از پروتكل IPX استفاده شده باشد، می بايست به هر VLAN شماره شبكه IPX مربوطه را نسبت داد. شايد اين سوال در ذهن شما مطرح شده باشد كه با توجه به وجود سوئيچ چه دليلی برای استفاده از روتر وجود دارد؟ همانگونه كه در شكل فوق مشاهده می نمائيد، شبكه فوق دارای هفت VLAN و يا broadcast domain می باشد كه از شماره يك شروع می شوند. گره های موجود درون هر VLAN قادر به برقراری ارتباط با يكديگر می باشند ولی نه با ساير عناصر موجود در يك VLAN ديگر. به چه ابزاری نياز داريم تا اين امكان در اختيار هاست های موجود گذاشته شود تا با يك گره و يا هاست موجود بر روی يك شبكه متفاوت ديگر ارتباط برقرار نمايند؟ حدس شما صحيح است يك روتر. اين گره ها می بايست از طريق يك روتر و يا يك دستگاه لايه سه به هدف خود برسند (دقيقا مشابه زمانی كه برای ارتباطات VLAN پيكربندی شده اند). اين موضوع زمانی كه چندين شبكه فيزيكی مختلف را بخواهيم به يكديگر متصل نمائيم نيز وجود خواهد داشت. ارتباط بين هر يك از VLAN ها می بايست از طريق يك دستگاه لايه سه انجام شود.